| to | |||
|---|---|---|---|
| |||
| transliteration | to | ||
| translit. with dakuten | do | ||
| hiragana origin | 止 | ||
| katakana origin | 止 | ||
| Man'yōgana | 刀 土 斗 度 戸 利 速 止 等 登 澄 得 騰 十 鳥 常 跡 | ||
| Voiced Man'yōgana | 土 度 渡 奴 怒 特 藤 騰 等 耐 抒 杼 | ||
| spelling kana | 東京のト (Tōkyō no "to") | ||
| unicode | U+3068, U+30C8 | ||
| braille | |||
| Note: These Man'yōgana originally represented syllables with one of two different vowel sounds, which merged in later pronunciation | |||
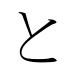
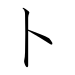
| kana gojūon | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Kana modifiers and marks | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Multi-syllabic kana | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
と, in hiragana, or ト in katakana, is one of the Japanese kana, each of which represents one mora. Both represent the sound [to], and when written with dakuten represent the sound [do]. In the Ainu language, the katakana ト can be written with a handakuten (which can be entered in a computer as either one character (ト゚) or two combined characters (ト゜) to represent the sound [tu], and is interchangeable with the katakana ツ゚.
| Form | Rōmaji | Hiragana | Katakana |
|---|---|---|---|
| Normal t- (た行 ta-gyō) |
to | と | ト |
| tou too tō |
とう とお, とぉ とー |
トウ トオ, トォ トー | |
| Addition dakuten d- (だ行 da-gyō) |
do | ど | ド |
| dou doo dō |
どう どお, どぉ どー |
ドウ ドオ, ドォ ドー |
| Other additional forms | |||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||||||||||||||||||||||||||
Stroke order
 Stroke order in writing と |
 Stroke order in writing ト |
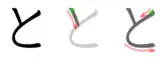
Stroke order in writing と

Stroke order in writing ト
The Katakana ト is made from two strokes:
- A vertical stroke on in the center;
- A line pointing downwards towards the right.
Other communicative representations
| Japanese radiotelephony alphabet | Wabun code |
| 東京のト Tōkyō no "To" |
ⓘ |
|
|
 |
 | |
| Japanese Navy Signal Flag | Japanese semaphore | Japanese manual syllabary (fingerspelling) | Braille dots-2345 Japanese Braille |
- Full Braille representation
| と / ト in Japanese Braille | |||||||
|---|---|---|---|---|---|---|---|
| と / ト to | ど / ド do | とう / トー tō/tou | どう / ドー dō/dou | Other kana based on Braille と | |||
| ちょ / チョ cho | ぢょ / ヂョ jo/dyo | ちょう / チョー chō | ぢょう / ヂョー jō/dyō | ||||
| Preview | と | ト | ト | ㋣ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | HIRAGANA LETTER TO | KATAKANA LETTER TO | HALFWIDTH KATAKANA LETTER TO | CIRCLED KATAKANA TO | ||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 12392 | U+3068 | 12488 | U+30C8 | 65412 | U+FF84 | 13027 | U+32E3 |
| UTF-8 | 227 129 168 | E3 81 A8 | 227 131 136 | E3 83 88 | 239 190 132 | EF BE 84 | 227 139 163 | E3 8B A3 |
| Numeric character reference | と | と | ト | ト | ト | ト | ㋣ | ㋣ |
| Shift JIS[1] | 130 198 | 82 C6 | 131 103 | 83 67 | 196 | C4 | ||
| EUC-JP[2] | 164 200 | A4 C8 | 165 200 | A5 C8 | 142 196 | 8E C4 | ||
| GB 18030[3] | 164 200 | A4 C8 | 165 200 | A5 C8 | 132 49 153 50 | 84 31 99 32 | ||
| EUC-KR[4] / UHC[5] | 170 200 | AA C8 | 171 200 | AB C8 | ||||
| Big5 (non-ETEN kana)[6] | 198 204 | C6 CC | 199 96 | C7 60 | ||||
| Big5 (ETEN / HKSCS)[7] | 199 79 | C7 4F | 199 196 | C7 C4 | ||||
| Preview | ㇳ | ど | ド | ト゚ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | KATAKANA LETTER SMALL TO | HIRAGANA LETTER DO | KATAKANA LETTER DO | KATAKANA LETTER AINU TO[8] | ||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 12787 | U+31F3 | 12393 | U+3069 | 12489 | U+30C9 | 12488 12442 | U+30C8+309A |
| UTF-8 | 227 135 179 | E3 87 B3 | 227 129 169 | E3 81 A9 | 227 131 137 | E3 83 89 | 227 131 136 227 130 154 | E3 83 88 E3 82 9A |
| Numeric character reference | ㇳ | ㇳ | ど | ど | ド | ド | ト | ト |
| Shift JIS (plain)[1] | 130 199 | 82 C7 | 131 104 | 83 68 | ||||
| Shift JIS-2004[9] | 131 239 | 83 EF | 130 199 | 82 C7 | 131 104 | 83 68 | 131 158 | 83 9E |
| EUC-JP (plain)[2] | 164 201 | A4 C9 | 165 201 | A5 C9 | ||||
| EUC-JIS-2004[10] | 166 241 | A6 F1 | 164 201 | A4 C9 | 165 201 | A5 C9 | 165 254 | A5 FE |
| GB 18030[3] | 129 57 188 55 | 81 39 BC 37 | 164 201 | A4 C9 | 165 201 | A5 C9 | ||
| EUC-KR[4] / UHC[5] | 170 201 | AA C9 | 171 201 | AB C9 | ||||
| Big5 (non-ETEN kana)[6] | 198 205 | C6 CD | 199 97 | C7 61 | ||||
| Big5 (ETEN / HKSCS)[7] | 199 80 | C7 50 | 199 197 | C7 C5 | ||||
References
- 1 2 Unicode Consortium (2015-12-02) [1994-03-08]. "Shift-JIS to Unicode".
- 1 2 Unicode Consortium; IBM. "EUC-JP-2007". International Components for Unicode.
- 1 2 Standardization Administration of China (SAC) (2005-11-18). GB 18030-2005: Information Technology—Chinese coded character set.
- 1 2 Unicode Consortium; IBM. "IBM-970". International Components for Unicode.
- 1 2 Steele, Shawn (2000). "cp949 to Unicode table". Microsoft / Unicode Consortium.
- 1 2 Unicode Consortium (2015-12-02) [1994-02-11]. "BIG5 to Unicode table (complete)".
- 1 2 van Kesteren, Anne. "big5". Encoding Standard. WHATWG.
- ↑ Unicode Consortium. "Unicode Named Character Sequences". Unicode Character Database.
- ↑ Project X0213 (2009-05-03). "Shift_JIS-2004 (JIS X 0213:2004 Appendix 1) vs Unicode mapping table".
{{cite web}}: CS1 maint: numeric names: authors list (link) - ↑ Project X0213 (2009-05-03). "EUC-JIS-2004 (JIS X 0213:2004 Appendix 3) vs Unicode mapping table".
{{cite web}}: CS1 maint: numeric names: authors list (link)
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.