Cover's theorem is a statement in computational learning theory and is one of the primary theoretical motivations for the use of non-linear kernel methods in machine learning applications. It is so termed after the information theorist Thomas M. Cover who stated it in 1965, referring to it as counting function theorem.
The Theorem
The theorem expresses the number of homogeneously linearly separable sets of points in dimensions as an explicit counting function of the number of points and the dimensionality .



It requires, as a necessary and sufficient condition, that the points are in general position. Simply put, this means that the points should be as linearly independent (non-aligned) as possible. This condition is satisfied "with probability 1" or almost surely for random point sets, while it may easily be violated for real data, since these are often structured along smaller-dimensionality manifolds within the data space.
The function follows two different regimes depending on the relationship between and .
- For , the function is exponential in . This essentially means that any set of labelled points in general position and in number no larger than the dimensionality + 1 is linearly separable; in jargon, it is said that a linear classifier shatters any point set with . This limiting quantity is also known as the Vapnik-Chervonenkis dimension of the linear classifier.

- For , the counting function starts growing less than exponentially . This means that, given a sample of fixed size , for larger dimensionality it is more probable that a random set of labelled points is linearly separable. Conversely, with fixed dimensionality, for larger sample sizes the number of linearly separable sets of random points will be smaller, or in other words the probability to find a linearly separable sample will decrease with .

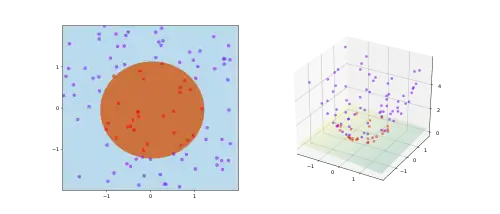
A consequence of the theorem is that given a set of training data that is not linearly separable, one can with high probability transform it into a training set that is linearly separable by projecting it into a higher-dimensional space via some non-linear transformation, or:
A complex pattern-classification problem, cast in a high-dimensional space nonlinearly, is more likely to be linearly separable than in a low-dimensional space, provided that the space is not densely populated.
Proof
The proof of Cover's counting function theorem can be obtained from the recursive relation

To show that, with fixed , increasing may turn a set of points from non-separable to separable, a deterministic mapping may be used: suppose there are points. Lift them onto the vertices of the simplex in the dimensional real space. Since every partition of the samples into two sets is separable by a linear separator, the property follows.

See also
References
- Haykin, Simon (2009). Neural Networks and Learning Machines (Third ed.). Upper Saddle River, New Jersey: Pearson Education Inc. pp. 232–236. ISBN 978-0-13-147139-9.
- Cover, T.M. (1965). "Geometrical and Statistical properties of systems of linear inequalities with applications in pattern recognition" (PDF). IEEE Transactions on Electronic Computers. EC-14 (3): 326–334. doi:10.1109/pgec.1965.264137. S2CID 18251470. Archived from the original (PDF) on 2019-12-20.
- Mehrotra, K.; Mohan, C. K.; Ranka, S. (1997). Elements of artificial neural networks (2nd ed.). MIT Press. ISBN 0-262-13328-8. (Section 3.5)