The nucleic acid notation currently in use was first formalized by the International Union of Pure and Applied Chemistry (IUPAC) in 1970.[1] This universally accepted notation uses the Roman characters G, C, A, and T, to represent the four nucleotides commonly found in deoxyribonucleic acids (DNA).
Given the rapidly expanding role for genetic sequencing, synthesis, and analysis in biology, some researchers have developed alternate notations to further support the analysis and manipulation of genetic data. These notations generally exploit size, shape, and symmetry to accomplish these objectives.
IUPAC notation
| Description | Symbol | Bases represented | Complementary bases | ||||
|---|---|---|---|---|---|---|---|
| No. | A | C | G | T | |||
| Adenine | A | 1 | A | T | |||
| Cytosine | C | C | G | ||||
| Guanine | G | G | C | ||||
| Thymine | T | T | A | ||||
| Uracil | U | U | A | ||||
| Weak | W | 2 | A | T | W | ||
| Strong | S | C | G | S | |||
| Amino | M | A | C | K | |||
| Ketone | K | G | T | M | |||
| Purine | R | A | G | Y | |||
| Pyrimidine | Y | C | T | R | |||
| Not A | B | 3 | C | G | T | V | |
| Not C | D | A | G | T | H | ||
| Not G | H | A | C | T | D | ||
| Not T[lower-alpha 1] | V | A | C | G | B | ||
| Any one base | N | 4 | A | C | G | T | N |
| Gap | - | 0 | - | ||||
| |||||||
Degenerate base symbols in biochemistry are an IUPAC[2][3] representation for a position on a DNA sequence that can have multiple possible alternatives. These should not be confused with non-canonical bases because each particular sequence will have in fact one of the regular bases. These are used to encode the consensus sequence of a population of aligned sequences and are used for example in phylogenetic analysis to summarise into one multiple sequences or for BLAST searches, even though IUPAC degenerate symbols are masked (as they are not coded).
Under the commonly used IUPAC system, nucleobases are represented by the first letters of their chemical names: guanine, cytosine, adenine, and thymine.[1] This shorthand also includes eleven "ambiguity" characters associated with every possible combination of the four DNA bases.[4] The ambiguity characters were designed to encode positional variations in order to report DNA sequencing errors, consensus sequences, or single-nucleotide polymorphisms. The IUPAC notation, including ambiguity characters and suggested mnemonics, is shown in Table 1.
Despite its broad and nearly universal acceptance, the IUPAC system has a number of limitations, which stem from its reliance on the Roman alphabet. The poor legibility of upper-case Roman characters, which are generally used when displaying genetic data, may be chief among these limitations. The value of external projections in distinguishing letters has been well documented.[5] However, these projections are absent from upper case letters, which in some cases are only distinguishable by subtle internal cues. Take for example the upper case C and G used to represent cytosine and guanine. These characters generally comprise half the characters in a genetic sequence but are differentiated by a small internal tick (depending on the typeface). Nevertheless, these Roman characters are available in the ASCII character set most commonly used in textual communications, which reinforces this system's ubiquity.
Another shortcoming of the IUPAC notation arises from the fact that its eleven ambiguity characters have been selected from the remaining characters of the Roman alphabet. The authors of the notation endeavored to select ambiguity characters with logical mnemonics. For example, S is used to represent the possibility of finding cytosine or guanine at genetic loci, both of which form strong cross-strand binding interactions. Conversely, the weaker interactions of thymine and adenine are represented by a W. However, convenient mnemonics are not as readily available for the other ambiguity characters displayed in Table 1. This has made ambiguity characters difficult to use and may account for their limited application.
Nucleic acid nomenclature
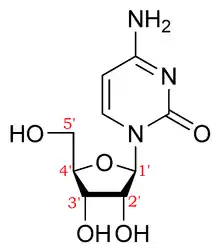
The positions of the carbons in the ribose sugar that forms the backbone of the nucleic acid chain are numbered, and are used to indicate the direction of nucleic acids (5'->3' versus 3'->5'). This is referred to as directionality.[3]
Alternative visually enhanced notations
Legibility issues associated with IUPAC-encoded genetic data have led biologists to consider alternative strategies for displaying genetic data. These creative approaches to visualizing DNA sequences have generally relied on the use of spatially distributed symbols and/or visually distinct shapes to encode lengthy nucleic acid sequences. Alternative notations for nucleotide sequences have been attempted, however general uptake has been low. Several of these approaches are summarized below.
Stave projection

In 1986, Cowin et al. described a novel method for visualizing DNA sequence known as the Stave Projection.[6] Their strategy was to encode nucleotides as circles on series of horizontal bars akin to notes on musical stave. As illustrated in Figure 1, each gap on the five-line staff corresponded to one of the four DNA bases. The spatial distribution of the circles made it far easier to distinguish individual bases and compare genetic sequences than IUPAC-encoded data.
The order of the bases (from top to bottom, G, A, T, C) is chosen so that the complementary strand can be read by turning the projection upside down.
Geometric symbols
Zimmerman et al. took a different approach to visualizing genetic data.[7] Rather than relying on spatially distributed circles to highlight genetic features, they exploited four geometrically diverse symbols found in a standard computer font to distinguish the four bases. The authors developed a simple WordPerfect macro to translate IUPAC characters into the more visually distinct symbols.
DNA Skyline
With the growing availability of font editors, Jarvius and Landegren devised a novel set of genetic symbols, known as the DNA Skyline font, which uses increasingly taller blocks to represent the different DNA bases.[8] While reminiscent of Cowin et al.'s spatially distributed Stave Projection, the DNA Skyline font is easy to download and permits translation to and from the IUPAC notation by simply changing the font in most standard word processing applications.
Ambigraphic notations
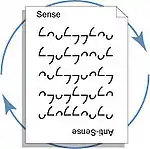
Ambigrams (symbols that convey different meaning when viewed in a different orientation) have been designed to mirror structural symmetries found in the DNA double helix.[9] By assigning ambigraphic characters to complementary bases (i.e. guanine: b, cytosine: q, adenine: n, and thymine: u), it is possible to complement DNA sequences by simply rotating the text 180 degrees.[10] An ambigraphic nucleic acid notation also makes it easy to identify genetic palindromes, such as endonuclease restriction sites, as sections of text that can be rotated 180 degrees without changing the sequence.
One example of an ambigraphic nucleic acid notation is AmbiScript, a rationally designed nucleic acid notations that combined many of the visual and functional features of its predecessors.[11] Its notation also uses spatially offset characters to facilitate the visual review and analysis of genetic data. AmbiScript was also designed to indicate ambiguous nucleotide positions via compound symbols. This strategy aimed to offer a more intuitive solution to the use of ambiguity characters first proposed by the IUPAC.[4] As with Jarvius and Landegren's DNA Skyline fonts, AmbiScript fonts can be downloaded and applied to IUPAC-encoded sequence data.
Triple Helix Base Pairing
Watson and Crick base pairs are indicated by a "•" or a "-" or a "." (example: A•T, or poly(rC)•2poly(rC)).
Hoogsteen triple helix base pairs are indicated by a "*" or a ":" (example: C•G*G+, or T•A*T, or C•G*G, or T•A*A).
See also
References
- 1 2 IUPAC-IUB Commission on Biochemical Nomenclature (1970). "Abbreviations and symbols for nucleic acids, polynucleotides, and their constituents". Biochemistry. 9 (20): 4022–4027. doi:10.1021/bi00822a023.
- 1 2 Nomenclature Committee of the International Union of Biochemistry (NC-IUB) (1984). "Nomenclature for Incompletely Specified Bases in Nucleic Acid Sequences". Nucleic Acids Research. 13 (9): 3021–3030. doi:10.1093/nar/13.9.3021. PMC 341218. PMID 2582368.
- 1 2 Cornish-Bowden A (May 1985). "Nomenclature for incompletely specified bases in nucleic acid sequences: recommendations 1984". Nucleic Acids Research. 13 (9): 3021–30. doi:10.1093/nar/13.9.3021. PMC 341218. PMID 2582368.
- 1 2 Nomenclature Committee of the International Union of Biochemistry (NC-IUB) (1986). "Nomenclature for incompletely specified bases in nucleic acid sequences. Recommendations 1984". Proc. Natl. Acad. Sci. USA. 83 (1): 4–8. Bibcode:1986PNAS...83....4O. doi:10.1073/pnas.83.1.4. PMC 322779. PMID 2417239.
- ↑ Tinker, M. A. 1963. Legibility of Print. Iowa State University Press, Ames IA.
- ↑ Cowin, J. E.; Jellis, C. H.; Rickwood, D. (1986). "A new method of representing DNA sequences which combines ease of visual analysis with machine readability". Nucleic Acids Research. 14 (1): 509–15. doi:10.1093/nar/14.1.509. PMC 339435. PMID 3003680.
- ↑ Zimmerman, P. A.; Spell, M. L.; Rawls, J.; Unnasch, T. R. (1991). "Transformation of DNA sequence data into geometric symbols". BioTechniques. 11 (1): 50–52. PMID 1954017.
- ↑ Jarvius, J.; Landegren, U. (2006). "DNA Skyline: fonts to facilitate visual inspection of nucleic acid sequences". BioTechniques. 40 (6): 740. doi:10.2144/000112180. PMID 16774117.
- ↑ Hofstadter, Douglas R. (1985). Metamagical Themas: Questioning the Essence of Mind and Pattern. New York: Basic Books. ISBN 978-0465045662.
- ↑ Rozak, D. A. (2006). "The practical and pedagogical advantages of an ambigraphic nucleic acid notation". Nucleosides, Nucleotides & Nucleic Acids. 25 (7): 807–813. doi:10.1080/15257770600726109. PMID 16898419. S2CID 23600737.
- ↑ Rozak, David A.; Rozak, Anthony J. (2008). "Simplicity, function, and legibility in an enhanced ambigraphic nucleic acid notation". BioTechniques. 44 (6): 811–813. doi:10.2144/000112727. PMID 18476835.
Branches of chemistry | |
|---|---|
| Analytical | |
| Theoretical | |
| Physical | |
| Inorganic | |
| Organic | |
| Biological | |
| Interdisciplinarity | |
| See also | |