| Part of a series on | |||||||
| Arithmetic logic circuits | |||||||
|---|---|---|---|---|---|---|---|
| Quick navigation | |||||||
|
Components
|
|||||||
|
Categories
|
|||||||
|
See also |
|||||||
A binary multiplier is an electronic circuit used in digital electronics, such as a computer, to multiply two binary numbers.
A variety of computer arithmetic techniques can be used to implement a digital multiplier. Most techniques involve computing the set of partial products, which are then summed together using binary adders. This process is similar to long multiplication, except that it uses a base-2 (binary) numeral system.
History
Between 1947 and 1949 Arthur Alec Robinson worked for English Electric Ltd, as a student apprentice, and then as a development engineer. Crucially during this period he studied for a PhD degree at the University of Manchester, where he worked on the design of the hardware multiplier for the early Mark 1 computer. However, until the late 1970s, most minicomputers did not have a multiply instruction, and so programmers used a "multiply routine"[1][2][3] which repeatedly shifts and accumulates partial results, often written using loop unwinding. Mainframe computers had multiply instructions, but they did the same sorts of shifts and adds as a "multiply routine".
Early microprocessors also had no multiply instruction. Though the multiply instruction became common with the 16-bit generation,[4] at least two 8-bit processors have a multiply instruction: the Motorola 6809, introduced in 1978,[5] and Intel MCS-51 family, developed in 1980, and later the modern Atmel AVR 8-bit microprocessors present in the ATMega, ATTiny and ATXMega microcontrollers.
As more transistors per chip became available due to larger-scale integration, it became possible to put enough adders on a single chip to sum all the partial products at once, rather than reuse a single adder to handle each partial product one at a time.
Because some common digital signal processing algorithms spend most of their time multiplying, digital signal processor designers sacrifice considerable chip area in order to make the multiply as fast as possible; a single-cycle multiply–accumulate unit often used up most of the chip area of early DSPs.
Binary long multiplication
The method taught in school for multiplying decimal numbers is based on calculating partial products, shifting them to the left and then adding them together. The most difficult part is to obtain the partial products, as that involves multiplying a long number by one digit (from 0 to 9):
123
× 456
=====
738 (this is 123 × 6)
615 (this is 123 × 5, shifted one position to the left)
+ 492 (this is 123 × 4, shifted two positions to the left)
=====
56088
A binary computer does exactly the same multiplication as decimal numbers do, but with binary numbers. In binary encoding each long number is multiplied by one digit (either 0 or 1), and that is much easier than in decimal, as the product by 0 or 1 is just 0 or the same number. Therefore, the multiplication of two binary numbers comes down to calculating partial products (which are 0 or the first number), shifting them left, and then adding them together (a binary addition, of course):
1011 (this is binary for decimal 11)
× 1110 (this is binary for decimal 14)
======
0000 (this is 1011 × 0)
1011 (this is 1011 × 1, shifted one position to the left)
1011 (this is 1011 × 1, shifted two positions to the left)
+ 1011 (this is 1011 × 1, shifted three positions to the left)
=========
10011010 (this is binary for decimal 154)
This is much simpler than in the decimal system, as there is no table of multiplication to remember: just shifts and adds.
This method is mathematically correct and has the advantage that a small CPU may perform the multiplication by using the shift and add features of its arithmetic logic unit rather than a specialized circuit. The method is slow, however, as it involves many intermediate additions. These additions are time-consuming. Faster multipliers may be engineered in order to do fewer additions; a modern processor can multiply two 64-bit numbers with 6 additions (rather than 64), and can do several steps in parallel.
The second problem is that the basic school method handles the sign with a separate rule ("+ with + yields +", "+ with − yields −", etc.). Modern computers embed the sign of the number in the number itself, usually in the two's complement representation. That forces the multiplication process to be adapted to handle two's complement numbers, and that complicates the process a bit more. Similarly, processors that use ones' complement, sign-and-magnitude, IEEE-754 or other binary representations require specific adjustments to the multiplication process.
Unsigned integers
For example, suppose we want to multiply two unsigned 8-bit integers together: a[7:0] and b[7:0]. We can produce eight partial products by performing eight 1-bit multiplications, one for each bit in multiplicand a:
p0[7:0] = a[0] × b[7:0] = {8{a[0]}} & b[7:0]
p1[7:0] = a[1] × b[7:0] = {8{a[1]}} & b[7:0]
p2[7:0] = a[2] × b[7:0] = {8{a[2]}} & b[7:0]
p3[7:0] = a[3] × b[7:0] = {8{a[3]}} & b[7:0]
p4[7:0] = a[4] × b[7:0] = {8{a[4]}} & b[7:0]
p5[7:0] = a[5] × b[7:0] = {8{a[5]}} & b[7:0]
p6[7:0] = a[6] × b[7:0] = {8{a[6]}} & b[7:0]
p7[7:0] = a[7] × b[7:0] = {8{a[7]}} & b[7:0]
where {8{a[0]}} means repeating a[0] (the 0th bit of a) 8 times (Verilog notation).
In order to obtain our product, we then need to add up all eight of our partial products, as shown here:
p0[7] p0[6] p0[5] p0[4] p0[3] p0[2] p0[1] p0[0]
+ p1[7] p1[6] p1[5] p1[4] p1[3] p1[2] p1[1] p1[0] 0
+ p2[7] p2[6] p2[5] p2[4] p2[3] p2[2] p2[1] p2[0] 0 0
+ p3[7] p3[6] p3[5] p3[4] p3[3] p3[2] p3[1] p3[0] 0 0 0
+ p4[7] p4[6] p4[5] p4[4] p4[3] p4[2] p4[1] p4[0] 0 0 0 0
+ p5[7] p5[6] p5[5] p5[4] p5[3] p5[2] p5[1] p5[0] 0 0 0 0 0
+ p6[7] p6[6] p6[5] p6[4] p6[3] p6[2] p6[1] p6[0] 0 0 0 0 0 0
+ p7[7] p7[6] p7[5] p7[4] p7[3] p7[2] p7[1] p7[0] 0 0 0 0 0 0 0
-------------------------------------------------------------------------------------------
P[15] P[14] P[13] P[12] P[11] P[10] P[9] P[8] P[7] P[6] P[5] P[4] P[3] P[2] P[1] P[0]
In other words, P[15:0] is produced by summing p0, p1 << 1, p2 << 2, and so forth, to produce our final unsigned 16-bit product.
Signed integers
If b had been a signed integer instead of an unsigned integer, then the partial products would need to have been sign-extended up to the width of the product before summing. If a had been a signed integer, then partial product p7 would need to be subtracted from the final sum, rather than added to it.
The above array multiplier can be modified to support two's complement notation signed numbers by inverting several of the product terms and inserting a one to the left of the first partial product term:
1 ~p0[7] p0[6] p0[5] p0[4] p0[3] p0[2] p0[1] p0[0]
~p1[7] +p1[6] +p1[5] +p1[4] +p1[3] +p1[2] +p1[1] +p1[0] 0
~p2[7] +p2[6] +p2[5] +p2[4] +p2[3] +p2[2] +p2[1] +p2[0] 0 0
~p3[7] +p3[6] +p3[5] +p3[4] +p3[3] +p3[2] +p3[1] +p3[0] 0 0 0
~p4[7] +p4[6] +p4[5] +p4[4] +p4[3] +p4[2] +p4[1] +p4[0] 0 0 0 0
~p5[7] +p5[6] +p5[5] +p5[4] +p5[3] +p5[2] +p5[1] +p5[0] 0 0 0 0 0
~p6[7] +p6[6] +p6[5] +p6[4] +p6[3] +p6[2] +p6[1] +p6[0] 0 0 0 0 0 0
1 +p7[7] ~p7[6] ~p7[5] ~p7[4] ~p7[3] ~p7[2] ~p7[1] ~p7[0] 0 0 0 0 0 0 0
------------------------------------------------------------------------------------------------------------
P[15] P[14] P[13] P[12] P[11] P[10] P[9] P[8] P[7] P[6] P[5] P[4] P[3] P[2] P[1] P[0]
Where ~p represents the complement (opposite value) of p.
There are many simplifications in the bit array above that are not shown and are not obvious. The sequences of one complemented bit followed by noncomplemented bits are implementing a two's complement trick to avoid sign extension. The sequence of p7 (noncomplemented bit followed by all complemented bits) is because we're subtracting this term so they were all negated to start out with (and a 1 was added in the least significant position). For both types of sequences, the last bit is flipped and an implicit −1 should be added directly below the MSB. When the +1 from the two's complement negation for p7 in bit position 0 (LSB) and all the −1's in bit columns 7 through 14 (where each of the MSBs are located) are added together, they can be simplified to the single 1 that "magically" is floating out to the left. For an explanation and proof of why flipping the MSB saves us the sign extension, see a computer arithmetic book.[6]
Floating-point numbers
A binary floating-point number contains a sign bit, significant bits (known as the significand) and exponent bits (for simplicity, we don't consider base and combination field). The sign bits of each operand are XOR'd to get the sign of the answer. Then, the two exponents are added to get the exponent of the result. Finally, multiplication of each operand's significand will return the significand of the result. However, if the result of the binary multiplication is higher than the total number of bits for a specific precision (e.g. 32, 64, 128), rounding is required and the exponent is changed appropriately.
Hardware implementation
The process of multiplication can be split into 3 steps:[7][8]
- generating partial product
- reducing partial product
- computing final product
Older multiplier architectures employed a shifter and accumulator to sum each partial product, often one partial product per cycle, trading off speed for die area. Modern multiplier architectures use the (Modified) Baugh–Wooley algorithm,[9][10][11][12] Wallace trees, or Dadda multipliers to add the partial products together in a single cycle. The performance of the Wallace tree implementation is sometimes improved by modified Booth encoding one of the two multiplicands, which reduces the number of partial products that must be summed.
For speed, shift-and-add multipliers require a fast adder (something faster than ripple-carry).[13]
A "single cycle" multiplier (or "fast multiplier") is pure combinational logic.
In a fast multiplier, the partial-product reduction process usually contributes the most to the delay, power, and area of the multiplier.[7] For speed, the "reduce partial product" stages are typically implemented as a carry-save adder composed of compressors and the "compute final product" step is implemented as a fast adder (something faster than ripple-carry).
Many fast multipliers use full adders as compressors ("3:2 compressors") implemented in static CMOS. To achieve better performance in the same area or the same performance in a smaller area, multiplier designs may use higher order compressors such as 7:3 compressors;[8][7] implement the compressors in faster logic (such transmission gate logic, pass transistor logic, domino logic);[13] connect the compressors in a different pattern; or some combination.
Example circuits
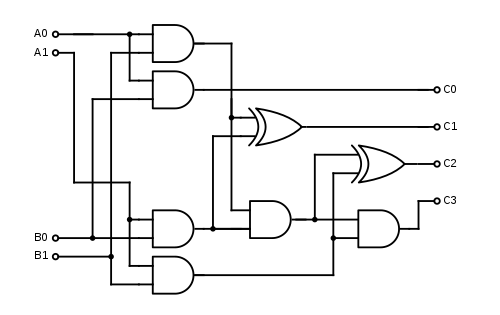
See also
- Booth's multiplication algorithm
- Fused multiply–add
- Wallace tree
- BKM algorithm for complex logarithms and exponentials
- Kochanski multiplication for modular multiplication
- Logical shift left
References
- ↑ Rather, Elizabeth D.; Colburn, Donald R.; Moore, Charles H. (1996) [1993]. "The evolution of Forth". In Bergin, Thomas J.; Gibson, Richard G. (eds.). History of programming languages---II. Association for Computing Machinery. pp. 625–670. doi:10.1145/234286.1057832. ISBN 0201895021.
- ↑ Davies, A.C.; Fung, Y.T. (1977). "Interfacing a hardware multiplier to a general-purpose microprocessor". Microprocessors. 1 (7): 425–432. doi:10.1016/0308-5953(77)90004-6.
- ↑ Rafiquzzaman, M. (2005). "§2.5.1 Binary Arithmetic: Multiplication of Unsigned Binary Numbers". Fundamentals of Digital Logic and Microcomputer Design. Wiley. p. 46. ISBN 978-0-47173349-2.
- ↑ Rafiquzzaman 2005, §7.3.3 Addition, Subtraction, Multiplication and Division of Signed and Unsigned Numbers p. 251
- ↑ Kant, Krishna (2007). "§2.11.2 16-Bit Microprocessors". Microprocessors and Microcontrollers: Architecture, Programming and System Design 8085, 8086, 8051, 8096. PHI Learning. p. 57. ISBN 9788120331914.
- ↑ Parhami, Behrooz (2000). Computer Arithmetic: Algorithms and Hardware Designs. Oxford University Press. ISBN 0-19-512583-5.
- 1 2 3 Rouholamini, Mahnoush; Kavehie, Omid; Mirbaha, Amir-Pasha; Jasbi, Somaye Jafarali; Navi, Keivan. "A New Design for 7:2 Compressors" (PDF).
- 1 2 Leong, Yuhao; Lo, HaiHiung; Drieberg, Michael; Sayuti, Abu Bakar; Sebastian, Patrick. "Performance Comparison Review of 8-3 compressor on FPGA".
- ↑ Baugh, Charles Richmond; Wooley, Bruce A. (December 1973). "A Two's Complement Parallel Array Multiplication Algorithm". IEEE Transactions on Computers. C-22 (12): 1045–1047. doi:10.1109/T-C.1973.223648. S2CID 7473784.
- ↑ Hatamian, Mehdi; Cash, Glenn (1986). "A 70-MHz 8-bit×8-bit parallel pipelined multiplier in 2.5-μm CMOS". IEEE Journal of Solid-State Circuits. 21 (4): 505–513. Bibcode:1986IJSSC..21..505H. doi:10.1109/jssc.1986.1052564.
- ↑ Gebali, Fayez (2003). "Baugh–Wooley Multiplier" (PDF). University of Victoria, CENG 465 Lab 2. Archived (PDF) from the original on 2018-04-14. Retrieved 2018-04-14.
- ↑ Reynders, Nele; Dehaene, Wim (2015). Ultra-Low-Voltage Design of Energy-Efficient Digital Circuits. Analog Circuits and Signal Processing. Springer. doi:10.1007/978-3-319-16136-5. ISBN 978-3-319-16135-8. ISSN 1872-082X. LCCN 2015935431.
- 1 2 Peng Chang. "A Reconfigurable Digital Multiplier and 4:2 Compressor Cells Design". 2008.
- Hennessy, John L.; Patterson, David A. (1990). "Section A.2, section A.9". Computer Architecture: A quantitative Approach. Morgan Kaufmann. pp. A–3..A–6, A–39..A–49. ISBN 978-0-12383872-8.