Hyperlink-Induced Topic Search (HITS; also known as hubs and authorities) is a link analysis algorithm that rates Web pages, developed by Jon Kleinberg. The idea behind Hubs and Authorities stemmed from a particular insight into the creation of web pages when the Internet was originally forming; that is, certain web pages, known as hubs, served as large directories that were not actually authoritative in the information that they held, but were used as compilations of a broad catalog of information that led users direct to other authoritative pages. In other words, a good hub represents a page that pointed to many other pages, while a good authority represents a page that is linked by many different hubs.[1]
The scheme therefore assigns two scores for each page: its authority, which estimates the value of the content of the page, and its hub value, which estimates the value of its links to other pages.
History
In journals
Many methods have been used to rank the importance of scientific journals. One such method is Garfield's impact factor. Journals such as Science and Nature are filled with numerous citations, making these magazines have very high impact factors. Thus, when comparing two more obscure journals which have received roughly the same number of citations but one of these journals has received many citations from Science and Nature, this journal needs be ranked higher. In other words, it is better to receive citations from an important journal than from an unimportant one.[2]
On the Web
This phenomenon also occurs in the Internet. Counting the number of links to a page can give us a general estimate of its prominence on the Web, but a page with very few incoming links may also be prominent, if two of these links come from the home pages of sites like Yahoo!, Google, or MSN. Because these sites are of very high importance but are also search engines, a page can be ranked much higher than its actual relevance.
Algorithm
Steps
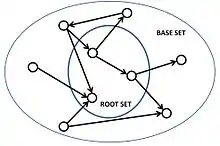
In the HITS algorithm, the first step is to retrieve the most relevant pages to the search query. This set is called the root set and can be obtained by taking the top pages returned by a text-based search algorithm. A base set is generated by augmenting the root set with all the web pages that are linked from it and some of the pages that link to it. The web pages in the base set and all hyperlinks among those pages form a focused subgraph. The HITS computation is performed only on this focused subgraph. According to Kleinberg the reason for constructing a base set is to ensure that most (or many) of the strongest authorities are included.
Authority and hub values are defined in terms of one another in a mutual recursion. An authority value is computed as the sum of the scaled hub values that point to that page. A hub value is the sum of the scaled authority values of the pages it points to. Some implementations also consider the relevance of the linked pages.
The algorithm performs a series of iterations, each consisting of two basic steps:
- Authority update: Update each node's authority score to be equal to the sum of the hub scores of each node that points to it. That is, a node is given a high authority score by being linked from pages that are recognized as Hubs for information.
- Hub update: Update each node's hub score to be equal to the sum of the authority scores of each node that it points to. That is, a node is given a high hub score by linking to nodes that are considered to be authorities on the subject.
The Hub score and Authority score for a node is calculated with the following algorithm:
- Start with each node having a hub score and authority score of 1.
- Run the authority update rule
- Run the hub update rule
- Normalize the values by dividing each Hub score by square root of the sum of the squares of all Hub scores, and dividing each Authority score by square root of the sum of the squares of all Authority scores.
- Repeat from the second step as necessary.
Comparison to PageRank
HITS, like Page and Brin's PageRank, is an iterative algorithm based on the linkage of the documents on the web. However it does have some major differences:
- It is processed on a small subset of ‘relevant’ documents (a 'focused subgraph' or base set), instead of the set of all documents as was the case with PageRank.
- It is query-dependent: the same page can receive a different hub/authority score given a different base set, which appears for a different query;
- It must, as a corollary, be executed at query time, not at indexing time, with the associated drop in performance that accompanies query-time processing.
- It computes two scores per document (hub and authority) as opposed to a single score;
- It is not commonly used by search engines (though a similar algorithm was said to be used by Teoma, which was acquired by Ask Jeeves/Ask.com).
In detail
To begin the ranking, we let and for each page . We consider two types of updates: Authority Update Rule and Hub Update Rule. In order to calculate the hub/authority scores of each node, repeated iterations of the Authority Update Rule and the Hub Update Rule are applied. A k-step application of the Hub-Authority algorithm entails applying for k times first the Authority Update Rule and then the Hub Update Rule.



Authority update rule
For each , we update to where is all pages which link to page . That is, a page's authority score is the sum of all the hub scores of pages that point to it.



Hub update rule
For each , we update to where is all pages which page links to. That is, a page's hub score is the sum of all the authority scores of pages it points to.



Normalization
The final hub-authority scores of nodes are determined after infinite repetitions of the algorithm. As directly and iteratively applying the Hub Update Rule and Authority Update Rule leads to diverging values, it is necessary to normalize the matrix after every iteration. Thus the values obtained from this process will eventually converge.
Pseudocode
G := set of pages
for each page p in G do
p.auth = 1 // p.auth is the authority score of the page p
p.hub = 1 // p.hub is the hub score of the page p
for step from 1 to k do // run the algorithm for k steps
norm = 0
for each page p in G do // update all authority values first
p.auth = 0
for each page q in p.incomingNeighbors do // p.incomingNeighbors is the set of pages that link to p
p.auth += q.hub
norm += square(p.auth) // calculate the sum of the squared auth values to normalise
norm = sqrt(norm)
for each page p in G do // update the auth scores
p.auth = p.auth / norm // normalise the auth values
norm = 0
for each page p in G do // then update all hub values
p.hub = 0
for each page r in p.outgoingNeighbors do // p.outgoingNeighbors is the set of pages that p links to
p.hub += r.auth
norm += square(p.hub) // calculate the sum of the squared hub values to normalise
norm = sqrt(norm)
for each page p in G do // then update all hub values
p.hub = p.hub / norm // normalise the hub values
The hub and authority values converge in the pseudocode above.
The code below does not converge, because it is necessary to limit the number of steps that the algorithm runs for. One way to get around this, however, would be to normalize the hub and authority values after each "step" by dividing each authority value by the square root of the sum of the squares of all authority values, and dividing each hub value by the square root of the sum of the squares of all hub values. This is what the pseudocode above does.
Non-converging pseudocode
G := set of pages
for each page p in G do
p.auth = 1 // p.auth is the authority score of the page p
p.hub = 1 // p.hub is the hub score of the page p
function HubsAndAuthorities(G)
for step from 1 to k do // run the algorithm for k steps
for each page p in G do // update all authority values first
p.auth = 0
for each page q in p.incomingNeighbors do // p.incomingNeighbors is the set of pages that link to p
p.auth += q.hub
for each page p in G do // then update all hub values
p.hub = 0
for each page r in p.outgoingNeighbors do // p.outgoingNeighbors is the set of pages that p links to
p.hub += r.auth
See also
References
- ↑ Christopher D. Manning; Prabhakar Raghavan; Hinrich Schütze (2008). "Introduction to Information Retrieval". Cambridge University Press. Retrieved 2008-11-09.
- ↑ Kleinberg, Jon (December 1999). "Hubs, Authorities, and Communities". Cornell University. Retrieved 2008-11-09.
- Kleinberg, Jon (1999). "Authoritative sources in a hyperlinked environment" (PDF). Journal of the ACM. 46 (5): 604–632. CiteSeerX 10.1.1.54.8485. doi:10.1145/324133.324140. S2CID 221584113.
- Li, L.; Shang, Y.; Zhang, W. (2002). "Improvement of HITS-based Algorithms on Web Documents". Proceedings of the 11th International World Wide Web Conference (WWW 2002). Honolulu, HI. ISBN 978-1-880672-20-4. Archived from the original on 2005-04-03. Retrieved 2005-06-03.
{{cite book}}: CS1 maint: location missing publisher (link)
External links
- U.S. Patent 6,112,202
- Create a data search engine from a relational database Search engine in C# based on HITS