
In mathematics, Jensen's inequality, named after the Danish mathematician Johan Jensen, relates the value of a convex function of an integral to the integral of the convex function. It was proved by Jensen in 1906,[1] building on an earlier proof of the same inequality for doubly-differentiable functions by Otto Hölder in 1889.[2] Given its generality, the inequality appears in many forms depending on the context, some of which are presented below. In its simplest form the inequality states that the convex transformation of a mean is less than or equal to the mean applied after convex transformation; it is a simple corollary that the opposite is true of concave transformations.[3]
Jensen's inequality generalizes the statement that the secant line of a convex function lies above the graph of the function, which is Jensen's inequality for two points: the secant line consists of weighted means of the convex function (for t ∈ [0,1]),

while the graph of the function is the convex function of the weighted means,

Thus, Jensen's inequality is

In the context of probability theory, it is generally stated in the following form: if X is a random variable and φ is a convex function, then
![{\displaystyle \varphi (\operatorname {E} [X])\leq \operatorname {E} \left[\varphi (X)\right].}](../I/e7526369e9c0a915459648a6817fc1b78faf9408.svg)
The difference between the two sides of the inequality, , is called the Jensen gap.[4]
![{\displaystyle \operatorname {E} \left[\varphi (X)\right]-\varphi \left(\operatorname {E} [X]\right)}](../I/9c3d0eb81dbbf440cd2080fad70d027557cd59a7.svg)
Statements
The classical form of Jensen's inequality involves several numbers and weights. The inequality can be stated quite generally using either the language of measure theory or (equivalently) probability. In the probabilistic setting, the inequality can be further generalized to its full strength.
Finite form
For a real convex function , numbers in its domain, and positive weights , Jensen's inequality can be stated as:



-
(1)

and the inequality is reversed if is concave, which is
-
(2)

Equality holds if and only if or is linear on a domain containing .


As a particular case, if the weights are all equal, then (1) and (2) become
-
(3)

-
(4)

For instance, the function log(x) is concave, so substituting in the previous formula (4) establishes the (logarithm of the) familiar arithmetic-mean/geometric-mean inequality:

![{\displaystyle \log \!\left({\frac {\sum _{i=1}^{n}x_{i}}{n}}\right)\geq {\frac {\sum _{i=1}^{n}\log \!\left(x_{i}\right)}{n}}\quad {\text{or}}\quad {\frac {x_{1}+x_{2}+\cdots +x_{n}}{n}}\geq {\sqrt[{n}]{x_{1}\cdot x_{2}\cdots x_{n}}}}](../I/003b2f8e45abb37d818932b892f4c62f119f8e5c.svg)
A common application has x as a function of another variable (or set of variables) t, that is, . All of this carries directly over to the general continuous case: the weights ai are replaced by a non-negative integrable function f (x), such as a probability distribution, and the summations are replaced by integrals.

Measure-theoretic form
Let be a probability space. Let be a -measurable function and be convex. Then:[5]





In real analysis, we may require an estimate on

where , and is a non-negative Lebesgue-integrable function. In this case, the Lebesgue measure of need not be unity. However, by integration by substitution, the interval can be rescaled so that it has measure unity. Then Jensen's inequality can be applied to get[6]

![{\displaystyle f\colon [a,b]\to \mathbb {R} }](../I/c5ab61178bf5349838758ffe3d96135406ed0245.svg)
![[a,b]](../I/9c4b788fc5c637e26ee98b45f89a5c08c85f7935.svg)

Probabilistic form
The same result can be equivalently stated in a probability theory setting, by a simple change of notation. Let be a probability space, X an integrable real-valued random variable and φ a convex function. Then:

![{\displaystyle \varphi \left(\operatorname {E} [X]\right)\leq \operatorname {E} \left[\varphi (X)\right].}](../I/0ccf5ccf34d01dc72d23f89f6b762b9dc389d21b.svg)
In this probability setting, the measure μ is intended as a probability , the integral with respect to μ as an expected value , and the function as a random variable X.



Note that the equality holds if and only if φ is a linear function on some convex set such that (which follows by inspecting the measure-theoretical proof below).


General inequality in a probabilistic setting
More generally, let T be a real topological vector space, and X a T-valued integrable random variable. In this general setting, integrable means that there exists an element in T, such that for any element z in the dual space of T: , and . Then, for any measurable convex function φ and any sub-σ-algebra of :
![\operatorname {E} [X]](../I/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93.svg)

![{\displaystyle \langle z,\operatorname {E} [X]\rangle =\operatorname {E} [\langle z,X\rangle ]}](../I/7c2a44da29485fcda2021bf260db54b4a924605b.svg)


![{\displaystyle \varphi \left(\operatorname {E} \left[X\mid {\mathfrak {G}}\right]\right)\leq \operatorname {E} \left[\varphi (X)\mid {\mathfrak {G}}\right].}](../I/7559de684e66ffdf0538b08fb52c03725ddd3009.svg)
Here stands for the expectation conditioned to the σ-algebra . This general statement reduces to the previous ones when the topological vector space T is the real axis, and is the trivial σ-algebra {∅, Ω} (where ∅ is the empty set, and Ω is the sample space).[8]
![{\displaystyle \operatorname {E} [\cdot \mid {\mathfrak {G}}]}](../I/651f1f8a0789e98598458aeeff4787451a1126b4.svg)
A sharpened and generalized form
Let X be a one-dimensional random variable with mean and variance . Let be a twice differentiable function, and define the function



Then[9]
![{\displaystyle \sigma ^{2}\inf {\frac {\varphi ''(x)}{2}}\leq \sigma ^{2}\inf h(x)\leq E\left[\varphi \left(X\right)\right]-\varphi \left(E[X]\right)\leq \sigma ^{2}\sup h(x)\leq \sigma ^{2}\sup {\frac {\varphi ''(x)}{2}}.}](../I/f2e66b0fdcef4b3fd89bd6e0e78499a7c07cb22a.svg)
In particular, when is convex, then , and the standard form of Jensen's inequality immediately follows for the case where is additionally assumed to be twice differentiable.

Proofs
Intuitive graphical proof
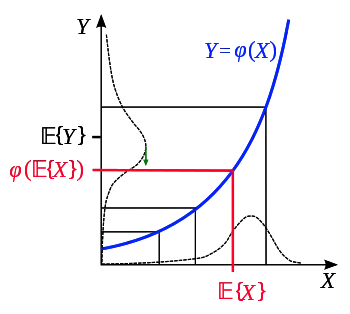

Jensen's inequality can be proved in several ways, and three different proofs corresponding to the different statements above will be offered. Before embarking on these mathematical derivations, however, it is worth analyzing an intuitive graphical argument based on the probabilistic case where X is a real number (see figure). Assuming a hypothetical distribution of X values, one can immediately identify the position of and its image in the graph. Noticing that for convex mappings Y = φ(x) of some x values the corresponding distribution of Y values is increasingly "stretched up" for increasing values of X, it is easy to see that the distribution of Y is broader in the interval corresponding to X > X0 and narrower in X < X0 for any X0; in particular, this is also true for . Consequently, in this picture the expectation of Y will always shift upwards with respect to the position of . A similar reasoning holds if the distribution of X covers a decreasing portion of the convex function, or both a decreasing and an increasing portion of it. This "proves" the inequality, i.e.
![{\displaystyle \varphi (\operatorname {E} [X])}](../I/61c1053fa4b89fa3970677fd7da9f9bbee273e37.svg)
![{\displaystyle X_{0}=\operatorname {E} [X]}](../I/d01bcf4cfdc01c112bbef291d68f4889aa1b8eb6.svg)
![{\displaystyle \varphi (\operatorname {E} [X])\leq \operatorname {E} [\varphi (X)]=\operatorname {E} [Y],}](../I/bd3e3171e918c98be483cfc1a8e26fee7dbdc031.svg)
with equality when φ(X) is not strictly convex, e.g. when it is a straight line, or when X follows a degenerate distribution (i.e. is a constant).
The proofs below formalize this intuitive notion.
Proof 1 (finite form)
If λ1 and λ2 are two arbitrary nonnegative real numbers such that λ1 + λ2 = 1 then convexity of φ implies

This can be generalized: if λ1, ..., λn are nonnegative real numbers such that λ1 + ... + λn = 1, then

for any x1, ..., xn.
The finite form of the Jensen's inequality can be proved by induction: by convexity hypotheses, the statement is true for n = 2. Suppose the statement is true for some n, so

for any λ1, ..., λn such that λ1 + ... + λn = 1.
One needs to prove it for n + 1. At least one of the λi is strictly smaller than , say λn+1; therefore by convexity inequality:


Since λ1 + ... +λn + λn+1 = 1,
- ,

applying the inductive hypothesis gives

therefore

We deduce the equality is true for n + 1, by induction it follows that the result is also true for all integer n greater than 2.
In order to obtain the general inequality from this finite form, one needs to use a density argument. The finite form can be rewritten as:

where μn is a measure given by an arbitrary convex combination of Dirac deltas:

Since convex functions are continuous, and since convex combinations of Dirac deltas are weakly dense in the set of probability measures (as could be easily verified), the general statement is obtained simply by a limiting procedure.
Proof 2 (measure-theoretic form)
Let be a real-valued -integrable function on a probability space , and let be a convex function on the real numbers. Since is convex, at each real number we have a nonempty set of subderivatives, which may be thought of as lines touching the graph of at , but which are below the graph of at all points (support lines of the graph).



Now, if we define

because of the existence of subderivatives for convex functions, we may choose and such that



for all real and

But then we have that

for almost all . Since we have a probability measure, the integral is monotone with so that



as desired.
Proof 3 (general inequality in a probabilistic setting)
Let X be an integrable random variable that takes values in a real topological vector space T. Since is convex, for any , the quantity



is decreasing as θ approaches 0+. In particular, the subdifferential of evaluated at x in the direction y is well-defined by

It is easily seen that the subdifferential is linear in y (that is false and the assertion requires Hahn-Banach theorem to be proved) and, since the infimum taken in the right-hand side of the previous formula is smaller than the value of the same term for θ = 1, one gets

In particular, for an arbitrary sub-σ-algebra we can evaluate the last inequality when to obtain
![{\displaystyle x=\operatorname {E} [X\mid {\mathfrak {G}}],\,y=X-\operatorname {E} [X\mid {\mathfrak {G}}]}](../I/6734e570e889ceff890ae029f56517150b424af3.svg)
![{\displaystyle \varphi (\operatorname {E} [X\mid {\mathfrak {G}}])\leq \varphi (X)-(D\varphi )(\operatorname {E} [X\mid {\mathfrak {G}}])\cdot (X-\operatorname {E} [X\mid {\mathfrak {G}}]).}](../I/8bd565d7189a3f9e4de1aa3ecff1dea1778dbdc5.svg)
Now, if we take the expectation conditioned to on both sides of the previous expression, we get the result since:
![{\displaystyle \operatorname {E} \left[\left[(D\varphi )(\operatorname {E} [X\mid {\mathfrak {G}}])\cdot (X-\operatorname {E} [X\mid {\mathfrak {G}}])\right]\mid {\mathfrak {G}}\right]=(D\varphi )(\operatorname {E} [X\mid {\mathfrak {G}}])\cdot \operatorname {E} [\left(X-\operatorname {E} [X\mid {\mathfrak {G}}]\right)\mid {\mathfrak {G}}]=0,}](../I/8777b883b9d0d4074c710cbb74234cdedd47cbe5.svg)
by the linearity of the subdifferential in the y variable, and the following well-known property of the conditional expectation:
![{\displaystyle \operatorname {E} \left[\left(\operatorname {E} [X\mid {\mathfrak {G}}]\right)\mid {\mathfrak {G}}\right]=\operatorname {E} [X\mid {\mathfrak {G}}].}](../I/95e8bb3de1968e40b8a4e8a5e478c503d6c39255.svg)
Applications and special cases
Form involving a probability density function
Suppose Ω is a measurable subset of the real line and f(x) is a non-negative function such that

In probabilistic language, f is a probability density function.
Then Jensen's inequality becomes the following statement about convex integrals:
If g is any real-valued measurable function and is convex over the range of g, then


If g(x) = x, then this form of the inequality reduces to a commonly used special case:

This is applied in Variational Bayesian methods.
Example: even moments of a random variable
If g(x) = x2n, and X is a random variable, then g is convex as

and so
![{\displaystyle g(\operatorname {E} [X])=(\operatorname {E} [X])^{2n}\leq \operatorname {E} [X^{2n}].}](../I/79aa21f43c09557f3e7d89fe582e89ddceedceb2.svg)
In particular, if some even moment 2n of X is finite, X has a finite mean. An extension of this argument shows X has finite moments of every order dividing n.

Alternative finite form
Let Ω = {x1, ... xn}, and take μ to be the counting measure on Ω, then the general form reduces to a statement about sums:

provided that λi ≥ 0 and

There is also an infinite discrete form.
Statistical physics
Jensen's inequality is of particular importance in statistical physics when the convex function is an exponential, giving:
![{\displaystyle e^{\operatorname {E} [X]}\leq \operatorname {E} \left[e^{X}\right],}](../I/d3fe012f87c0e66ecf1a528f992a96821b865346.svg)
where the expected values are with respect to some probability distribution in the random variable X.
Proof: Let in

Information theory
If p(x) is the true probability density for X, and q(x) is another density, then applying Jensen's inequality for the random variable Y(X) = q(X)/p(X) and the convex function φ(y) = −log(y) gives
![{\displaystyle \operatorname {E} [\varphi (Y)]\geq \varphi (\operatorname {E} [Y])}](../I/2a8e10448892007ab55caaac214eb65aac6b319c.svg)
Therefore:

a result called Gibbs' inequality.
It shows that the average message length is minimised when codes are assigned on the basis of the true probabilities p rather than any other distribution q. The quantity that is non-negative is called the Kullback–Leibler divergence of q from p.
Since −log(x) is a strictly convex function for x > 0, it follows that equality holds when p(x) equals q(x) almost everywhere.
Rao–Blackwell theorem
If L is a convex function and a sub-sigma-algebra, then, from the conditional version of Jensen's inequality, we get
![{\displaystyle L(\operatorname {E} [\delta (X)\mid {\mathfrak {G}}])\leq \operatorname {E} [L(\delta (X))\mid {\mathfrak {G}}]\quad \Longrightarrow \quad \operatorname {E} [L(\operatorname {E} [\delta (X)\mid {\mathfrak {G}}])]\leq \operatorname {E} [L(\delta (X))].}](../I/89afb9f259b4f81f325a13f12885b369451b9669.svg)
So if δ(X) is some estimator of an unobserved parameter θ given a vector of observables X; and if T(X) is a sufficient statistic for θ; then an improved estimator, in the sense of having a smaller expected loss L, can be obtained by calculating
![{\displaystyle \delta _{1}(X)=\operatorname {E} _{\theta }[\delta (X')\mid T(X')=T(X)],}](../I/64c079c8deebb9e2ceba4593a6abd6a8fa81b439.svg)
the expected value of δ with respect to θ, taken over all possible vectors of observations X compatible with the same value of T(X) as that observed. Further, because T is a sufficient statistics, does not depend on θ, hence, becomes a statistics.

This result is known as the Rao–Blackwell theorem.
See also
- Karamata's inequality for a more general inequality
- Popoviciu's inequality
- Law of averages
- A proof without words of Jensen's inequality
Notes
- ↑ Jensen, J. L. W. V. (1906). "Sur les fonctions convexes et les inégalités entre les valeurs moyennes". Acta Mathematica. 30 (1): 175–193. doi:10.1007/BF02418571.
- ↑ Guessab, A.; Schmeisser, G. (2013). "Necessary and sufficient conditions for the validity of Jensen's inequality". Archiv der Mathematik. 100 (6): 561–570. doi:10.1007/s00013-013-0522-3. MR 3069109. S2CID 56372266.
- ↑ Dekking, F.M.; Kraaikamp, C.; Lopuhaa, H.P.; Meester, L.E. (2005). A Modern Introduction to Probability and Statistics: Understanding Why and How. Springer Texts in Statistics. London: Springer. doi:10.1007/1-84628-168-7. ISBN 978-1-85233-896-1.
- ↑ Gao, Xiang; Sitharam, Meera; Roitberg, Adrian (2019). "Bounds on the Jensen Gap, and Implications for Mean-Concentrated Distributions" (PDF). The Australian Journal of Mathematical Analysis and Applications. 16 (2). arXiv:1712.05267.
- ↑ p. 25 of Rick Durrett (2019). Probability: Theory and Examples (5th ed.). Cambridge University Press. ISBN 978-1108473682.
- ↑ Niculescu, Constantin P. "Integral inequalities", P. 12.
- ↑ p. 29 of Rick Durrett (2019). Probability: Theory and Examples (5th ed.). Cambridge University Press. ISBN 978-1108473682.
- ↑ Attention: In this generality additional assumptions on the convex function and/ or the topological vector space are needed, see Example (1.3) on p. 53 in Perlman, Michael D. (1974). "Jensen's Inequality for a Convex Vector-Valued Function on an Infinite-Dimensional Space". Journal of Multivariate Analysis. 4 (1): 52–65. doi:10.1016/0047-259X(74)90005-0. hdl:11299/199167.
- ↑ Liao, J.; Berg, A (2018). "Sharpening Jensen's Inequality". American Statistician. 73 (3): 278–281. arXiv:1707.08644. doi:10.1080/00031305.2017.1419145. S2CID 88515366.
- ↑ Bradley, CJ (2006). Introduction to Inequalities. Leeds, United Kingdom: United Kingdom Mathematics Trust. p. 97. ISBN 978-1-906001-11-7.
References
- David Chandler (1987). Introduction to Modern Statistical Mechanics. Oxford. ISBN 0-19-504277-8.
- Tristan Needham (1993) "A Visual Explanation of Jensen's Inequality", American Mathematical Monthly 100(8):768–71.
- Nicola Fusco; Paolo Marcellini; Carlo Sbordone (1996). Analisi Matematica Due. Liguori. ISBN 978-88-207-2675-1.
- Walter Rudin (1987). Real and Complex Analysis. McGraw-Hill. ISBN 0-07-054234-1.
- Rick Durrett (2019). Probability: Theory and Examples (5th ed.). Cambridge University Press. p. 430. ISBN 978-1108473682. Retrieved 21 Dec 2020.
- Sam Savage (2012) The Flaw of Averages: Why We Underestimate Risk in the Face of Uncertainty (1st ed.) Wiley. ISBN 978-0471381976
External links
- Jensen's Operator Inequality of Hansen and Pedersen.
- "Jensen inequality", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Weisstein, Eric W. "Jensen's inequality". MathWorld.
- Arthur Lohwater (1982). "Introduction to Inequalities". Online e-book in PDF format.