In computer science, LR parsers are a type of bottom-up parser that analyse deterministic context-free languages in linear time.[1] There are several variants of LR parsers: SLR parsers, LALR parsers, canonical LR(1) parsers, minimal LR(1) parsers, and generalized LR parsers (GLR parsers). LR parsers can be generated by a parser generator from a formal grammar defining the syntax of the language to be parsed. They are widely used for the processing of computer languages.
An LR parser (left-to-right, rightmost derivation in reverse) reads input text from left to right without backing up (this is true for most parsers), and produces a rightmost derivation in reverse: it does a bottom-up parse – not a top-down LL parse or ad-hoc parse. The name "LR" is often followed by a numeric qualifier, as in "LR(1)" or sometimes "LR(k)". To avoid backtracking or guessing, the LR parser is allowed to peek ahead at k lookahead input symbols before deciding how to parse earlier symbols. Typically k is 1 and is not mentioned. The name "LR" is often preceded by other qualifiers, as in "SLR" and "LALR". The "LR(k)" notation for a grammar was suggested by Knuth to stand for "translatable from left to right with bound k."[1]
LR parsers are deterministic; they produce a single correct parse without guesswork or backtracking, in linear time. This is ideal for computer languages, but LR parsers are not suited for human languages which need more flexible but inevitably slower methods. Some methods which can parse arbitrary context-free languages (e.g., Cocke–Younger–Kasami, Earley, GLR) have worst-case performance of O(n3) time. Other methods which backtrack or yield multiple parses may even take exponential time when they guess badly.[2]
The above properties of L, R, and k are actually shared by all shift-reduce parsers, including precedence parsers. But by convention, the LR name stands for the form of parsing invented by Donald Knuth, and excludes the earlier, less powerful precedence methods (for example Operator-precedence parser).[1] LR parsers can handle a larger range of languages and grammars than precedence parsers or top-down LL parsing.[3] This is because the LR parser waits until it has seen an entire instance of some grammar pattern before committing to what it has found. An LL parser has to decide or guess what it is seeing much sooner, when it has only seen the leftmost input symbol of that pattern.
Overview
Bottom-up parse tree for example A*2 + 1
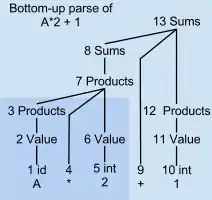
An LR parser scans and parses the input text in one forward pass over the text. The parser builds up the parse tree incrementally, bottom up, and left to right, without guessing or backtracking. At every point in this pass, the parser has accumulated a list of subtrees or phrases of the input text that have been already parsed. Those subtrees are not yet joined together because the parser has not yet reached the right end of the syntax pattern that will combine them.
At step 6 in an example parse, only "A*2" has been parsed, incompletely. Only the shaded lower-left corner of the parse tree exists. None of the parse tree nodes numbered 7 and above exist yet. Nodes 3, 4, and 6 are the roots of isolated subtrees for variable A, operator *, and number 2, respectively. These three root nodes are temporarily held in a parse stack. The remaining unparsed portion of the input stream is "+ 1".
Shift and reduce actions
As with other shift-reduce parsers, an LR parser works by doing some combination of Shift steps and Reduce steps.
- A Shift step advances in the input stream by one symbol. That shifted symbol becomes a new single-node parse tree.
- A Reduce step applies a completed grammar rule to some of the recent parse trees, joining them together as one tree with a new root symbol.
If the input has no syntax errors, the parser continues with these steps until all of the input has been consumed and all of the parse trees have been reduced to a single tree representing an entire legal input.
LR parsers differ from other shift-reduce parsers in how they decide when to reduce, and how to pick between rules with similar endings. But the final decisions and the sequence of shift or reduce steps are the same.
Much of the LR parser's efficiency is from being deterministic. To avoid guessing, the LR parser often looks ahead (rightwards) at the next scanned symbol, before deciding what to do with previously scanned symbols. The lexical scanner works one or more symbols ahead of the parser. The lookahead symbols are the 'right-hand context' for the parsing decision.[4]
Bottom-up parse stack
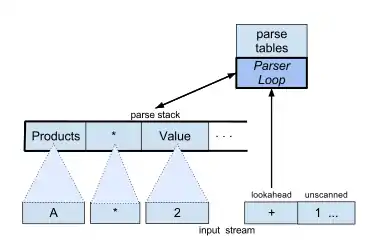
Like other shift-reduce parsers, an LR parser lazily waits until it has scanned and parsed all parts of some construct before committing to what the combined construct is. The parser then acts immediately on the combination instead of waiting any further. In the parse tree example, the phrase A gets reduced to Value and then to Products in steps 1-3 as soon as lookahead * is seen, rather than waiting any later to organize those parts of the parse tree. The decisions for how to handle A are based only on what the parser and scanner have already seen, without considering things that appear much later to the right.
Reductions reorganize the most recently parsed things, immediately to the left of the lookahead symbol. So the list of already-parsed things acts like a stack. This parse stack grows rightwards. The base or bottom of the stack is on the left and holds the leftmost, oldest parse fragment. Every reduction step acts only on the rightmost, newest parse fragments. (This accumulative parse stack is very unlike the predictive, leftward-growing parse stack used by top-down parsers.)
Bottom-up parse steps for example A*2 + 1
| Step | Parse Stack | Unparsed | Shift/Reduce |
|---|---|---|---|
| 0 | empty | A*2 + 1 | shift |
| 1 | id | *2 + 1 | Value → id |
| 2 | Value | *2 + 1 | Products → Value |
| 3 | Products | *2 + 1 | shift |
| 4 | Products * | 2 + 1 | shift |
| 5 | Products * int | + 1 | Value → int |
| 6 | Products * Value | + 1 | Products → Products * Value |
| 7 | Products | + 1 | Sums → Products |
| 8 | Sums | + 1 | shift |
| 9 | Sums + | 1 | shift |
| 10 | Sums + int | eof | Value → int |
| 11 | Sums + Value | eof | Products → Value |
| 12 | Sums + Products | eof | Sums → Sums + Products |
| 13 | Sums | eof | accept |
Step 6 applies a grammar rule with multiple parts:
- Products → Products * Value
This matches the stack top holding the parsed phrases "... Products * Value". The reduce step replaces this instance of the rule's right hand side, "Products * Value" by the rule's left hand side symbol, here a larger Products. If the parser builds complete parse trees, the three trees for inner Products, *, and Value are combined by a new tree root for Products. Otherwise, semantic details from the inner Products and Value are output to some later compiler pass, or are combined and saved in the new Products symbol.[5]
LR parse steps for example A*2 + 1
In LR parsers, the shift and reduce decisions are potentially based on the entire stack of everything that has been previously parsed, not just on a single, topmost stack symbol. If done in an unclever way, that could lead to very slow parsers that get slower and slower for longer inputs. LR parsers do this with constant speed, by summarizing all the relevant left context information into a single number called the LR(0) parser state. For each grammar and LR analysis method, there is a fixed (finite) number of such states. Besides holding the already-parsed symbols, the parse stack also remembers the state numbers reached by everything up to those points.
At every parse step, the entire input text is divided into a stack of previously parsed phrases, a current look-ahead symbol, and the remaining unscanned text. The parser's next action is determined by its current LR(0) state number (rightmost on the stack) and the lookahead symbol. In the steps below, all the black details are exactly the same as in other non-LR shift-reduce parsers. LR parser stacks add the state information in purple, summarizing the black phrases to their left on the stack and what syntax possibilities to expect next. Users of an LR parser can usually ignore state information. These states are explained in a later section.
Step | Parse Stack state [Symbolstate]* | Look Ahead | Unscanned | Parser Action | Grammar Rule | Next State |
|---|---|---|---|---|---|---|
| 0 |
0 |
id | *2 + 1 | shift | 9 | |
| 1 |
0 id9 |
* | 2 + 1 | reduce | Value → id | 7 |
| 2 |
0 Value7 |
* | 2 + 1 | reduce | Products → Value | 4 |
| 3 |
0 Products4 |
* | 2 + 1 | shift | 5 | |
| 4 |
0 Products4 *5 |
int | + 1 | shift | 8 | |
| 5 |
0 Products4 *5 int8 |
+ | 1 | reduce | Value → int | 6 |
| 6 |
0 Products4 *5 Value6 |
+ | 1 | reduce | Products → Products * Value | 4 |
| 7 |
0 Products4 |
+ | 1 | reduce | Sums → Products | 1 |
| 8 |
0 Sums1 |
+ | 1 | shift | 2 | |
| 9 |
0 Sums1 +2 |
int | eof | shift | 8 | |
| 10 |
0 Sums1 +2 int8 |
eof | reduce | Value → int | 7 | |
| 11 |
0 Sums1 +2 Value7 |
eof | reduce | Products → Value | 3 | |
| 12 |
0 Sums1 +2 Products3 |
eof | reduce | Sums → Sums + Products | 1 | |
| 13 |
0 Sums1 |
eof | accept | |||
At initial step 0, the input stream "A*2 + 1" is divided into
- an empty section on the parse stack,
- lookahead text "A" scanned as an id symbol, and
- the remaining unscanned text "*2 + 1".
The parse stack begins by holding only initial state 0. When state 0 sees the lookahead id, it knows to shift that id onto the stack, and scan the next input symbol *, and advance to state 9.
At step 4, the total input stream "A*2 + 1" is currently divided into
- the parsed section "A *" with 2 stacked phrases Products and *,
- lookahead text "2" scanned as an int symbol, and
- the remaining unscanned text " + 1".
The states corresponding to the stacked phrases are 0, 4, and 5. The current, rightmost state on the stack is state 5. When state 5 sees the lookahead int, it knows to shift that int onto the stack as its own phrase, and scan the next input symbol +, and advance to state 8.
At step 12, all of the input stream has been consumed but only partially organized. The current state is 3. When state 3 sees the lookahead eof, it knows to apply the completed grammar rule
- Sums → Sums + Products
by combining the stack's rightmost three phrases for Sums, +, and Products into one thing. State 3 itself doesn't know what the next state should be. This is found by going back to state 0, just to the left of the phrase being reduced. When state 0 sees this new completed instance of a Sums, it advances to state 1 (again). This consulting of older states is why they are kept on the stack, instead of keeping only the current state.
Grammar for the example A*2 + 1
LR parsers are constructed from a grammar that formally defines the syntax of the input language as a set of patterns. The grammar doesn't cover all language rules, such as the size of numbers, or the consistent use of names and their definitions in the context of the whole program. LR parsers use a context-free grammar that deals just with local patterns of symbols.
The example grammar used here is a tiny subset of the Java or C language:
- r0: Goal → Sums eof
- r1: Sums → Sums + Products
- r2: Sums → Products
- r3: Products → Products * Value
- r4: Products → Value
- r5: Value → int
- r6: Value → id
The grammar's terminal symbols are the multi-character symbols or 'tokens' found in the input stream by a lexical scanner. Here these include + * and int for any integer constant, and id for any identifier name, and eof for end of input file. The grammar doesn't care what the int values or id spellings are, nor does it care about blanks or line breaks. The grammar uses these terminal symbols but does not define them. They are always leaf nodes (at the bottom bushy end) of the parse tree.
The capitalized terms like Sums are nonterminal symbols. These are names for concepts or patterns in the language. They are defined in the grammar and never occur themselves in the input stream. They are always internal nodes (above the bottom) of the parse tree. They only happen as a result of the parser applying some grammar rule. Some nonterminals are defined with two or more rules; these are alternative patterns. Rules can refer back to themselves, which are called recursive. This grammar uses recursive rules to handle repeated math operators. Grammars for complete languages use recursive rules to handle lists, parenthesized expressions, and nested statements.
Any given computer language can be described by several different grammars. An LR(1) parser can handle many but not all common grammars. It is usually possible to manually modify a grammar so that it fits the limitations of LR(1) parsing and the generator tool.
The grammar for an LR parser must be unambiguous itself, or must be augmented by tie-breaking precedence rules. This means there is only one correct way to apply the grammar to a given legal example of the language, resulting in a unique parse tree with just one meaning, and a unique sequence of shift/reduce actions for that example. LR parsing is not a useful technique for human languages with ambiguous grammars that depend on the interplay of words. Human languages are better handled by parsers like Generalized LR parser, the Earley parser, or the CYK algorithm that can simultaneously compute all possible parse trees in one pass.
Parse table for the example grammar
Most LR parsers are table driven. The parser's program code is a simple generic loop that is the same for all grammars and languages. The knowledge of the grammar and its syntactic implications are encoded into unchanging data tables called parse tables (or parsing tables). Entries in a table show whether to shift or reduce (and by which grammar rule), for every legal combination of parser state and lookahead symbol. The parse tables also tell how to compute the next state, given just a current state and a next symbol.
The parse tables are much larger than the grammar. LR tables are hard to accurately compute by hand for big grammars. So they are mechanically derived from the grammar by some parser generator tool like Bison.[6]
Depending on how the states and parsing table are generated, the resulting parser is called either a SLR (simple LR) parser, LALR (look-ahead LR) parser, or canonical LR parser. LALR parsers handle more grammars than SLR parsers. Canonical LR parsers handle even more grammars, but use many more states and much larger tables. The example grammar is SLR.
LR parse tables are two-dimensional. Each current LR(0) parser state has its own row. Each possible next symbol has its own column. Some combinations of state and next symbol are not possible for valid input streams. These blank cells trigger syntax error messages.
The Action left half of the table has columns for lookahead terminal symbols. These cells determine whether the next parser action is shift (to state n), or reduce (by grammar rule rn).
The Goto right half of the table has columns for nonterminal symbols. These cells show which state to advance to, after some reduction's Left Hand Side has created an expected new instance of that symbol. This is like a shift action but for nonterminals; the lookahead terminal symbol is unchanged.
The table column "Current Rules" documents the meaning and syntax possibilities for each state, as worked out by the parser generator. It is not included in the actual tables used at parsing time. The • (pink dot) marker shows where the parser is now, within some partially recognized grammar rules. The things to the left of • have been parsed, and the things to the right are expected soon. A state has several such current rules if the parser has not yet narrowed possibilities down to a single rule.
| Curr | Lookahead | LHS Goto | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| State | Current Rules | int | id | * | + | eof | Sums | Products | Value | |
| 0 | Goal → • Sums eof | 8 | 9 | 1 | 4 | 7 | ||||
| 1 | Goal → Sums • eof Sums → Sums • + Products | 2 | accept | |||||||
| 2 | Sums → Sums + • Products | 8 | 9 | 3 | 7 | |||||
| 3 | Sums → Sums + Products • Products → Products • * Value | 5 | r1 | r1 | ||||||
| 4 | Sums → Products • Products → Products • * Value | 5 | r2 | r2 | ||||||
| 5 | Products → Products * • Value | 8 | 9 | 6 | ||||||
| 6 | Products → Products * Value • | r3 | r3 | r3 | ||||||
| 7 | Products → Value • | r4 | r4 | r4 | ||||||
| 8 | Value → int • | r5 | r5 | r5 | ||||||
| 9 | Value → id • | r6 | r6 | r6 | ||||||
In state 2 above, the parser has just found and shifted-in the + of grammar rule
- r1: Sums → Sums + • Products
The next expected phrase is Products. Products begins with terminal symbols int or id. If the lookahead is either of those, the parser shifts them in and advances to state 8 or 9, respectively. When a Products has been found, the parser advances to state 3 to accumulate the complete list of summands and find the end of rule r0. A Products can also begin with nonterminal Value. For any other lookahead or nonterminal, the parser announces a syntax error.
In state 3, the parser has just found a Products phrase, that could be from two possible grammar rules:
- r1: Sums → Sums + Products •
- r3: Products → Products • * Value
The choice between r1 and r3 can't be decided just from looking backwards at prior phrases. The parser has to check the lookahead symbol to tell what to do. If the lookahead is *, it is in rule 3, so the parser shifts in the * and advances to state 5. If the lookahead is eof, it is at the end of rule 1 and rule 0, so the parser is done.
In state 9 above, all the non-blank, non-error cells are for the same reduction r6. Some parsers save time and table space by not checking the lookahead symbol in these simple cases. Syntax errors are then detected somewhat later, after some harmless reductions, but still before the next shift action or parser decision.
Individual table cells must not hold multiple, alternative actions, otherwise the parser would be nondeterministic with guesswork and backtracking. If the grammar is not LR(1), some cells will have shift/reduce conflicts between a possible shift action and reduce action, or reduce/reduce conflicts between multiple grammar rules. LR(k) parsers resolve these conflicts (where possible) by checking additional lookahead symbols beyond the first.
LR parser loop
The LR parser begins with a nearly empty parse stack containing just the start state 0, and with the lookahead holding the input stream's first scanned symbol. The parser then repeats the following loop step until done, or stuck on a syntax error:
The topmost state on the parse stack is some state s, and the current lookahead is some terminal symbol t. Look up the next parser action from row s and column t of the Lookahead Action table. That action is either Shift, Reduce, Accept, or Error:
- Shift n:
- Shift the matched terminal t onto the parse stack and scan the next input symbol into the lookahead buffer.
- Push next state n onto the parse stack as the new current state.
- Reduce rm: Apply grammar rule rm: Lhs → S1 S2 ... SL
- Remove the matched topmost L symbols (and parse trees and associated state numbers) from the parse stack.
- This exposes a prior state p that was expecting an instance of the Lhs symbol.
- Join the L parse trees together as one parse tree with new root symbol Lhs.
- Lookup the next state n from row p and column Lhs of the LHS Goto table.
- Push the symbol and tree for Lhs onto the parse stack.
- Push next state n onto the parse stack as the new current state.
- The lookahead and input stream remain unchanged.
- Accept: Lookahead t is the eof marker. End of parsing. If the state stack contains just the start state report success. Otherwise, report a syntax error.
- Error: Report a syntax error. The parser ends, or attempts some recovery.
LR parser stack usually stores just the LR(0) automaton states, as the grammar symbols may be derived from them (in the automaton, all input transitions to some state are marked with the same symbol, which is the symbol associated with this state). Moreover, these symbols are almost never needed as the state is all that matters when making the parsing decision.[7]
LR generator analysis
This section of the article can be skipped by most users of LR parser generators.
LR states
State 2 in the example parse table is for the partially parsed rule
- r1: Sums → Sums + • Products
This shows how the parser got here, by seeing Sums then + while looking for a larger Sums. The • marker has advanced beyond the beginning of the rule. It also shows how the parser expects to eventually complete the rule, by next finding a complete Products. But more details are needed on how to parse all the parts of that Products.
The partially parsed rules for a state are called its "core LR(0) items". The parser generator adds additional rules or items for all the possible next steps in building up the expected Products:
- r3: Products → • Products * Value
- r4: Products → • Value
- r5: Value → • int
- r6: Value → • id
The • marker is at the beginning of each of these added rules; the parser has not yet confirmed and parsed any part of them. These additional items are called the "closure" of the core items. For each nonterminal symbol immediately following a •, the generator adds the rules defining that symbol. This adds more • markers, and possibly different follower symbols. This closure process continues until all follower symbols have been expanded. The follower nonterminals for state 2 begins with Products. Value is then added by closure. The follower terminals are int and id.
The kernel and closure items together show all possible legal ways to proceed from the current state to future states and complete phrases. If a follower symbol appears in only one item, it leads to a next state containing only one core item with the • marker advanced. So int leads to next state 8 with core
- r5: Value → int •
If the same follower symbol appears in several items, the parser cannot yet tell which rule applies here. So that symbol leads to a next state that shows all remaining possibilities, again with the • marker advanced. Products appears in both r1 and r3. So Products leads to next state 3 with core
- r1: Sums → Sums + Products •
- r3: Products → Products • * Value
In words, that means if the parser has seen a single Products, it might be done, or it might still have even more things to multiply together. All the core items have the same symbol preceding the • marker; all transitions into this state are always with that same symbol.
Some transitions will be to cores and states that have been enumerated already. Other transitions lead to new states. The generator starts with the grammar's goal rule. From there it keeps exploring known states and transitions until all needed states have been found.
These states are called "LR(0)" states because they use a lookahead of k=0, i.e. no lookahead. The only checking of input symbols occurs when the symbol is shifted in. Checking of lookaheads for reductions is done separately by the parse table, not by the enumerated states themselves.
Finite state machine
The parse table describes all possible LR(0) states and their transitions. They form a finite state machine (FSM). An FSM is a simple engine for parsing simple unnested languages, without using a stack. In this LR application, the FSM's modified "input language" has both terminal and nonterminal symbols, and covers any partially parsed stack snapshot of the full LR parse.
Recall step 5 of the Parse Steps Example:
Step | Parse Stack state Symbol state ... | Look Ahead | Unscanned |
|---|---|---|---|
| 5 |
0 Products4 *5 int8 |
+ | 1 |
The parse stack shows a series of state transitions, from the start state 0, to state 4 and then on to 5 and current state 8. The symbols on the parse stack are the shift or goto symbols for those transitions. Another way to view this, is that the finite state machine can scan the stream "Products * int + 1" (without using yet another stack) and find the leftmost complete phrase that should be reduced next. And that is indeed its job!
How can a mere FSM do this when the original unparsed language has nesting and recursion and definitely requires an analyzer with a stack? The trick is that everything to the left of the stack top has already been fully reduced. This eliminates all the loops and nesting from those phrases. The FSM can ignore all the older beginnings of phrases, and track just the newest phrases that might be completed next. The obscure name for this in LR theory is "viable prefix".
Lookahead sets
The states and transitions give all the needed information for the parse table's shift actions and goto actions. The generator also needs to calculate the expected lookahead sets for each reduce action.
In SLR parsers, these lookahead sets are determined directly from the grammar, without considering the individual states and transitions. For each nonterminal S, the SLR generator works out Follows(S), the set of all the terminal symbols which can immediately follow some occurrence of S. In the parse table, each reduction to S uses Follow(S) as its LR(1) lookahead set. Such follow sets are also used by generators for LL top-down parsers. A grammar that has no shift/reduce or reduce/reduce conflicts when using Follow sets is called an SLR grammar.
LALR parsers have the same states as SLR parsers, but use a more complicated, more precise way of working out the minimum necessary reduction lookaheads for each individual state. Depending on the details of the grammar, this may turn out to be the same as the Follow set computed by SLR parser generators, or it may turn out to be a subset of the SLR lookaheads. Some grammars are okay for LALR parser generators but not for SLR parser generators. This happens when the grammar has spurious shift/reduce or reduce/reduce conflicts using Follow sets, but no conflicts when using the exact sets computed by the LALR generator. The grammar is then called LALR(1) but not SLR.
An SLR or LALR parser avoids having duplicate states. But this minimization is not necessary, and can sometimes create unnecessary lookahead conflicts. Canonical LR parsers use duplicated (or "split") states to better remember the left and right context of a nonterminal's use. Each occurrence of a symbol S in the grammar can be treated independently with its own lookahead set, to help resolve reduction conflicts. This handles a few more grammars. Unfortunately, this greatly magnifies the size of the parse tables if done for all parts of the grammar. This splitting of states can also be done manually and selectively with any SLR or LALR parser, by making two or more named copies of some nonterminals. A grammar that is conflict-free for a canonical LR generator but has conflicts in an LALR generator is called LR(1) but not LALR(1), and not SLR.
SLR, LALR, and canonical LR parsers make exactly the same shift and reduce decisions when the input stream is the correct language. When the input has a syntax error, the LALR parser may do some additional (harmless) reductions before detecting the error than would the canonical LR parser. And the SLR parser may do even more. This happens because the SLR and LALR parsers are using a generous superset approximation to the true, minimal lookahead symbols for that particular state.
Syntax error recovery
LR parsers can generate somewhat helpful error messages for the first syntax error in a program, by simply enumerating all the terminal symbols that could have appeared next instead of the unexpected bad lookahead symbol. But this does not help the parser work out how to parse the remainder of the input program to look for further, independent errors. If the parser recovers badly from the first error, it is very likely to mis-parse everything else and produce a cascade of unhelpful spurious error messages.
In the yacc and bison parser generators, the parser has an ad hoc mechanism to abandon the current statement, discard some parsed phrases and lookahead tokens surrounding the error, and resynchronize the parse at some reliable statement-level delimiter like semicolons or braces. This often works well for allowing the parser and compiler to look over the rest of the program.
Many syntactic coding errors are simple typos or omissions of a trivial symbol. Some LR parsers attempt to detect and automatically repair these common cases. The parser enumerates every possible single-symbol insertion, deletion, or substitution at the error point. The compiler does a trial parse with each change to see if it worked okay. (This requires backtracking to snapshots of the parse stack and input stream, normally unneeded by the parser.) Some best repair is picked. This gives a very helpful error message and resynchronizes the parse well. However, the repair is not trustworthy enough to permanently modify the input file. Repair of syntax errors is easiest to do consistently in parsers (like LR) that have parse tables and an explicit data stack.
Variants of LR parsers
The LR parser generator decides what should happen for each combination of parser state and lookahead symbol. These decisions are usually turned into read-only data tables that drive a generic parser loop that is grammar- and state-independent. But there are also other ways to turn those decisions into an active parser.
Some LR parser generators create separate tailored program code for each state, rather than a parse table. These parsers can run several times faster than the generic parser loop in table-driven parsers. The fastest parsers use generated assembler code.
In the recursive ascent parser variation, the explicit parse stack structure is also replaced by the implicit stack used by subroutine calls. Reductions terminate several levels of subroutine calls, which is clumsy in most languages. So recursive ascent parsers are generally slower, less obvious, and harder to hand-modify than recursive descent parsers.
Another variation replaces the parse table by pattern-matching rules in non-procedural languages such as Prolog.
GLR Generalized LR parsers use LR bottom-up techniques to find all possible parses of input text, not just one correct parse. This is essential for ambiguous grammar such as used for human languages. The multiple valid parse trees are computed simultaneously, without backtracking. GLR is sometimes helpful for computer languages that are not easily described by a conflict-free LALR(1) grammar.
LC Left corner parsers use LR bottom-up techniques for recognizing the left end of alternative grammar rules. When the alternatives have been narrowed down to a single possible rule, the parser then switches to top-down LL(1) techniques for parsing the rest of that rule. LC parsers have smaller parse tables than LALR parsers and better error diagnostics. There are no widely used generators for deterministic LC parsers. Multiple-parse LC parsers are helpful with human languages with very large grammars.
Theory
LR parsers were invented by Donald Knuth in 1965 as an efficient generalization of precedence parsers. Knuth proved that LR parsers were the most general-purpose parsers possible that would still be efficient in the worst cases.
- "LR(k) grammars can be efficiently parsed with an execution time essentially proportional to the length of the string."[8]
- For every k≥1, "a language can be generated by an LR(k) grammar if and only if it is deterministic [and context-free], if and only if it can be generated by an LR(1) grammar."[9]
In other words, if a language was reasonable enough to allow an efficient one-pass parser, it could be described by an LR(k) grammar. And that grammar could always be mechanically transformed into an equivalent (but larger) LR(1) grammar. So an LR(1) parsing method was, in theory, powerful enough to handle any reasonable language. In practice, the natural grammars for many programming languages are close to being LR(1).
The canonical LR parsers described by Knuth had too many states and very big parse tables that were impractically large for the limited memory of computers of that era. LR parsing became practical when Frank DeRemer invented SLR and LALR parsers with much fewer states.[10][11]
For full details on LR theory and how LR parsers are derived from grammars, see The Theory of Parsing, Translation, and Compiling, Volume 1 (Aho and Ullman).[7][2]
Earley parsers apply the techniques and • notation of LR parsers to the task of generating all possible parses for ambiguous grammars such as for human languages.
While LR(k) grammars have equal generative power for all k≥1, the case of LR(0) grammars is slightly different. A language L is said to have the prefix property if no word in L is a proper prefix of another word in L.[12] A language L has an LR(0) grammar if and only if L is a deterministic context-free language with the prefix property.[13] As a consequence, a language L is deterministic context-free if and only if L$ has an LR(0) grammar, where "$" is not a symbol of L's alphabet.[14]
Additional example 1+1
This example of LR parsing uses the following small grammar with goal symbol E:
- (1) E → E * B
- (2) E → E + B
- (3) E → B
- (4) B → 0
- (5) B → 1
to parse the following input:
- 1 + 1
Action and goto tables
The two LR(0) parsing tables for this grammar look as follows:
| state | action | goto | |||||
| * | + | 0 | 1 | $ | E | B | |
| 0 | s1 | s2 | 3 | 4 | |||
| 1 | r4 | r4 | r4 | r4 | r4 | ||
| 2 | r5 | r5 | r5 | r5 | r5 | ||
| 3 | s5 | s6 | acc | ||||
| 4 | r3 | r3 | r3 | r3 | r3 | ||
| 5 | s1 | s2 | 7 | ||||
| 6 | s1 | s2 | 8 | ||||
| 7 | r1 | r1 | r1 | r1 | r1 | ||
| 8 | r2 | r2 | r2 | r2 | r2 | ||
The action table is indexed by a state of the parser and a terminal (including a special terminal $ that indicates the end of the input stream) and contains three types of actions:
- shift, which is written as "sn" and indicates that the next state is n
- reduce, which is written as "rm" and indicates that a reduction with grammar rule m should be performed
- accept, which is written as "acc" and indicates that the parser accepts the string in the input stream.
The goto table is indexed by a state of the parser and a nonterminal and simply indicates what the next state of the parser will be if it has recognized a certain nonterminal. This table is important to find out the next state after every reduction. After a reduction, the next state is found by looking up the goto table entry for top of the stack (i.e. current state) and the reduced rule's LHS (i.e. non-terminal).
Parsing steps
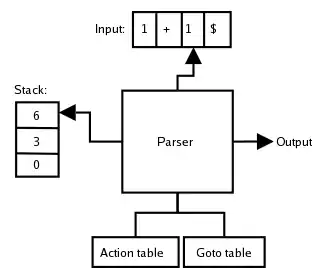
The table below illustrates each step in the process. Here the state refers to the element at the top of the stack (the right-most element), and the next action is determined by referring to the action table above. A $ is appended to the input string to denote the end of the stream.
| State | Input stream | Output stream | Stack | Next action |
|---|---|---|---|---|
| 0 | 1+1$ | [0] | Shift 2 | |
| 2 | +1$ | [0,2] | Reduce 5 | |
| 4 | +1$ | 5 | [0,4] | Reduce 3 |
| 3 | +1$ | 5,3 | [0,3] | Shift 6 |
| 6 | 1$ | 5,3 | [0,3,6] | Shift 2 |
| 2 | $ | 5,3 | [0,3,6,2] | Reduce 5 |
| 8 | $ | 5,3,5 | [0,3,6,8] | Reduce 2 |
| 3 | $ | 5,3,5,2 | [0,3] | Accept |
Walkthrough
The parser starts out with the stack containing just the initial state ('0'):
- [0]
The first symbol from the input string that the parser sees is '1'. To find the next action (shift, reduce, accept or error), the action table is indexed with the current state (the "current state" is just whatever is on the top of the stack), which in this case is 0, and the current input symbol, which is '1'. The action table specifies a shift to state 2, and so state 2 is pushed onto the stack (again, all the state information is in the stack, so "shifting to state 2" is the same as pushing 2 onto the stack). The resulting stack is
- [0 '1' 2]
where the top of the stack is 2. For the sake of explaining the symbol (e.g., '1', B) is shown that caused the transition to the next state, although strictly speaking it is not part of the stack.
In state 2, the action table says to reduce with grammar rule 5 (regardless of what terminal the parser sees on the input stream), which means that the parser has just recognized the right-hand side of rule 5. In this case, the parser writes 5 to the output stream, pops one state from the stack (since the right-hand side of the rule has one symbol), and pushes on the stack the state from the cell in the goto table for state 0 and B, i.e., state 4. The resulting stack is:
- [0 B 4]
However, in state 4, the action table says the parser should now reduce with rule 3. So it writes 3 to the output stream, pops one state from the stack, and finds the new state in the goto table for state 0 and E, which is state 3. The resulting stack:
- [0 E 3]
The next terminal that the parser sees is a '+' and according to the action table it should then shift to state 6:
- [0 E 3 '+' 6]
The resulting stack can be interpreted as the history of a finite state automaton that has just read a nonterminal E followed by a terminal '+'. The transition table of this automaton is defined by the shift actions in the action table and the goto actions in the goto table.
The next terminal is now '1' and this means that the parser performs a shift and go to state 2:
- [0 E 3 '+' 6 '1' 2]
Just as the previous '1' this one is reduced to B giving the following stack:
- [0 E 3 '+' 6 B 8]
The stack corresponds with a list of states of a finite automaton that has read a nonterminal E, followed by a '+' and then a nonterminal B. In state 8 the parser always performs a reduce with rule 2. The top 3 states on the stack correspond with the 3 symbols in the right-hand side of rule 2. This time we pop 3 elements off of the stack (since the right-hand side of the rule has 3 symbols) and look up the goto state for E and 0, thus pushing state 3 back onto the stack
- [0 E 3]
Finally, the parser reads a '$' (end of input symbol) from the input stream, which means that according to the action table (the current state is 3) the parser accepts the input string. The rule numbers that will then have been written to the output stream will be [5, 3, 5, 2] which is indeed a rightmost derivation of the string "1 + 1" in reverse.
Constructing LR(0) parsing tables
Items
The construction of these parsing tables is based on the notion of LR(0) items (simply called items here) which are grammar rules with a special dot added somewhere in the right-hand side. For example, the rule E → E + B has the following four corresponding items:
- E → • E + B
- E → E • + B
- E → E + • B
- E → E + B •
Rules of the form A → ε have only a single item A → •. The item E → E • + B, for example, indicates that the parser has recognized a string corresponding with E on the input stream and now expects to read a '+' followed by another string corresponding with B.
Item sets
It is usually not possible to characterize the state of the parser with a single item because it may not know in advance which rule it is going to use for reduction. For example, if there is also a rule E → E * B then the items E → E • + B and E → E • * B will both apply after a string corresponding with E has been read. Therefore, it is convenient to characterize the state of the parser by a set of items, in this case the set { E → E • + B, E → E • * B }.
Extension of Item Set by expansion of non-terminals
An item with a dot before a nonterminal, such as E → E + • B, indicates that the parser expects to parse the nonterminal B next. To ensure the item set contains all possible rules the parser may be in the midst of parsing, it must include all items describing how B itself will be parsed. This means that if there are rules such as B → 1 and B → 0 then the item set must also include the items B → • 1 and B → • 0. In general this can be formulated as follows:
- If there is an item of the form A → v • Bw in an item set and in the grammar there is a rule of the form B → w' then the item B → • w' should also be in the item set.
Closure of item sets
Thus, any set of items can be extended by recursively adding all the appropriate items until all nonterminals preceded by dots are accounted for. The minimal extension is called the closure of an item set and written as clos(I) where I is an item set. It is these closed item sets that are taken as the states of the parser, although only the ones that are actually reachable from the begin state will be included in the tables.
Augmented grammar
Before the transitions between the different states are determined, the grammar is augmented with an extra rule
- (0) S → E eof
where S is a new start symbol and E the old start symbol. The parser will use this rule for reduction exactly when it has accepted the whole input string.
For this example, the same grammar as above is augmented thus:
- (0) S → E eof
- (1) E → E * B
- (2) E → E + B
- (3) E → B
- (4) B → 0
- (5) B → 1
It is for this augmented grammar that the item sets and the transitions between them will be determined.
Table construction
Finding the reachable item sets and the transitions between them
The first step of constructing the tables consists of determining the transitions between the closed item sets. These transitions will be determined as if we are considering a finite automaton that can read terminals as well as nonterminals. The begin state of this automaton is always the closure of the first item of the added rule: S → • E eof:
- Item set 0
- S → • E eof
- + E → • E * B
- + E → • E + B
- + E → • B
- + B → • 0
- + B → • 1
The boldfaced "+" in front of an item indicates the items that were added for the closure (not to be confused with the mathematical '+' operator which is a terminal). The original items without a "+" are called the kernel of the item set.
Starting at the begin state (S0), all of the states that can be reached from this state are now determined. The possible transitions for an item set can be found by looking at the symbols (terminals and nonterminals) found following the dots; in the case of item set 0 those symbols are the terminals '0' and '1' and the nonterminals E and B. To find the item set that each symbol leads to, the following procedure is followed for each of the symbols:

- Take the subset, S, of all items in the current item set where there is a dot in front of the symbol of interest, x.
- For each item in S, move the dot to the right of x.
- Close the resulting set of items.
For the terminal '0' (i.e. where x = '0') this results in:
- Item set 1
- B → 0 •
and for the terminal '1' (i.e. where x = '1') this results in:
- Item set 2
- B → 1 •
and for the nonterminal E (i.e. where x = E) this results in:
- Item set 3
- S → E • eof
- E → E • * B
- E → E • + B
and for the nonterminal B (i.e. where x = B) this results in:
- Item set 4
- E → B •
The closure does not add new items in all cases - in the new sets above, for example, there are no nonterminals following the dot.
Above procedure is continued until no more new item sets are found. For the item sets 1, 2, and 4 there will be no transitions since the dot is not in front of any symbol. For item set 3 though, we have dots in front of terminals '*' and '+'. For symbol the transition goes to:

- Item set 5
- E → E * • B
- + B → • 0
- + B → • 1
and for the transition goes to:

- Item set 6
- E → E + • B
- + B → • 0
- + B → • 1
Now, the third iteration begins.
For item set 5, the terminals '0' and '1' and the nonterminal B must be considered, but the resulting closed item sets for the terminals are equal to already found item sets 1 and 2, respectively. For the nonterminal B, the transition goes to:
- Item set 7
- E → E * B •
For item set 6, the terminal '0' and '1' and the nonterminal B must be considered, but as before, the resulting item sets for the terminals are equal to the already found item sets 1 and 2. For the nonterminal B the transition goes to:
- Item set 8
- E → E + B •
These final item sets 7 and 8 have no symbols beyond their dots so no more new item sets are added, so the item generating procedure is complete. The finite automaton, with item sets as its states is shown below.
The transition table for the automaton now looks as follows:
| Item Set | * | + | 0 | 1 | E | B |
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | ||
| 1 | ||||||
| 2 | ||||||
| 3 | 5 | 6 | ||||
| 4 | ||||||
| 5 | 1 | 2 | 7 | |||
| 6 | 1 | 2 | 8 | |||
| 7 | ||||||
| 8 |
Constructing the action and goto tables
From this table and the found item sets, the action and goto table are constructed as follows:
- The columns for nonterminals are copied to the goto table.
- The columns for the terminals are copied to the action table as shift actions.
- An extra column for '$' (end of input) is added to the action table. An acc action is added to the '$' column for each item set that contains an item of the form S → w • eof.
- If an item set i contains an item of the form A → w • and A → w is rule m with m > 0 then the row for state i in the action table is completely filled with the reduce action rm.
The reader may verify that these steps produce the action and goto table presented earlier.
A note about LR(0) versus SLR and LALR parsing
Only step 4 of the above procedure produces reduce actions, and so all reduce actions must occupy an entire table row, causing the reduction to occur regardless of the next symbol in the input stream. This is why these are LR(0) parse tables: they don't do any lookahead (that is, they look ahead zero symbols) before deciding which reduction to perform. A grammar that needs lookahead to disambiguate reductions would require a parse table row containing different reduce actions in different columns, and the above procedure is not capable of creating such rows.
Refinements to the LR(0) table construction procedure (such as SLR and LALR) are capable of constructing reduce actions that do not occupy entire rows. Therefore, they are capable of parsing more grammars than LR(0) parsers.
Conflicts in the constructed tables
The automaton is constructed in such a way that it is guaranteed to be deterministic. However, when reduce actions are added to the action table it can happen that the same cell is filled with a reduce action and a shift action (a shift-reduce conflict) or with two different reduce actions (a reduce-reduce conflict). However, it can be shown that when this happens the grammar is not an LR(0) grammar. A classic real-world example of a shift-reduce conflict is the dangling else problem.
A small example of a non-LR(0) grammar with a shift-reduce conflict is:
- (1) E → 1 E
- (2) E → 1
One of the item sets found is:
- Item set 1
- E → 1 • E
- E → 1 •
- + E → • 1 E
- + E → • 1
There is a shift-reduce conflict in this item set: when constructing the action table according to the rules above, the cell for [item set 1, terminal '1'] contains s1 (shift to state 1) and r2 (reduce with grammar rule 2).
A small example of a non-LR(0) grammar with a reduce-reduce conflict is:
- (1) E → A 1
- (2) E → B 2
- (3) A → 1
- (4) B → 1
In this case the following item set is obtained:
- Item set 1
- A → 1 •
- B → 1 •
There is a reduce-reduce conflict in this item set because in the cells in the action table for this item set there will be both a reduce action for rule 3 and one for rule 4.
Both examples above can be solved by letting the parser use the follow set (see LL parser) of a nonterminal A to decide if it is going to use one of As rules for a reduction; it will only use the rule A → w for a reduction if the next symbol on the input stream is in the follow set of A. This solution results in so-called Simple LR parsers.
See also
References
- 1 2 3 Knuth, D. E. (July 1965). "On the translation of languages from left to right". Information and Control. 8 (6): 607–639. doi:10.1016/S0019-9958(65)90426-2.
- 1 2 Aho, Alfred V.; Ullman, Jeffrey D. (1972). The Theory of Parsing, Translation, and Compiling (Volume 1: Parsing.) (Repr. ed.). Englewood Cliffs, NJ: Prentice Hall. ISBN 978-0139145568.
- ↑ Language theoretic comparison of LL and LR grammars
- ↑ Engineering a Compiler (2nd edition), by Keith Cooper and Linda Torczon, Morgan Kaufmann 2011.
- ↑ Crafting and Compiler, by Charles Fischer, Ron Cytron, and Richard LeBlanc, Addison Wesley 2009.
- ↑ Flex & Bison: Text Processing Tools, by John Levine, O'Reilly Media 2009.
- 1 2 Compilers: Principles, Techniques, and Tools (2nd Edition), by Alfred Aho, Monica Lam, Ravi Sethi, and Jeffrey Ullman, Prentice Hall 2006.
- ↑ Knuth (1965), p.638
- ↑ Knuth (1965), p.635. Knuth didn't mention the restriction k≥1 there, but it is required by his theorems he referred to, viz. on p.629 and p.630. Similarly, the restriction to context-free languages is tacitly understood from the context.
- ↑ Practical Translators for LR(k) Languages, by Frank DeRemer, MIT PhD dissertation 1969.
- ↑ Simple LR(k) Grammars, by Frank DeRemer, Comm. ACM 14:7 1971.
- ↑ Hopcroft, John E.; Ullman, Jeffrey D. (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley. ISBN 0-201-02988-X. Here: Exercise 5.8, p.121.
- ↑ Hopcroft, Ullman (1979), Theorem 10.12, p.260
- ↑ Hopcroft, Ullman (1979), Corollary p.260
Further reading
- Chapman, Nigel P., LR Parsing: Theory and Practice, Cambridge University Press, 1987. ISBN 0-521-30413-X
- Pager, D., A Practical General Method for Constructing LR(k) Parsers. Acta Informatica 7, 249 - 268 (1977)
- "Compiler Construction: Principles and Practice" by Kenneth C. Louden. ISBN 0-534-939724
External links
- dickgrune.com, Parsing Techniques - A Practical Guide 1st Ed. web page of book includes downloadable pdf.
- Parsing Simulator This simulator is used to generate parsing tables LR and to resolve the exercises of the book
- Internals of an LALR(1) parser generated by GNU Bison - Implementation issues
- Course notes on LR parsing
- Shift-reduce and Reduce-reduce conflicts in an LALR parser
- A LR parser example
- Practical LR(k) Parser Construction
- The Honalee LR(k) Algorithm