In statistics, point estimation involves the use of sample data to calculate a single value (known as a point estimate since it identifies a point in some parameter space) which is to serve as a "best guess" or "best estimate" of an unknown population parameter (for example, the population mean). More formally, it is the application of a point estimator to the data to obtain a point estimate.
Point estimation can be contrasted with interval estimation: such interval estimates are typically either confidence intervals, in the case of frequentist inference, or credible intervals, in the case of Bayesian inference. More generally, a point estimator can be contrasted with a set estimator. Examples are given by confidence sets or credible sets. A point estimator can also be contrasted with a distribution estimator. Examples are given by confidence distributions, randomized estimators, and Bayesian posteriors.
Properties of point estimates
Biasedness
“Bias” is defined as the difference between the expected value of the estimator and the true value of the population parameter being estimated. It can also be described that the closer the expected value of a parameter is to the measured parameter, the lesser the bias. When the estimated number and the true value is equal, the estimator is considered unbiased. This is called an unbiased estimator. The estimator will become a best unbiased estimator if it has minimum variance. However, a biased estimator with a small variance may be more useful than an unbiased estimator with a large variance.[1] Most importantly, we prefer point estimators that have the smallest mean square errors.
If we let T = h(X1,X2, . . . , Xn) be an estimator based on a random sample X1,X2, . . . , Xn, the estimator T is called an unbiased estimator for the parameter θ if E[T] = θ, irrespective of the value of θ.[1] For example, from the same random sample we have E(x̄) = µ (mean) and E(s2) = σ2 (variance), then x̄ and s2 would be unbiased estimators for µ and σ2. The difference E[T ] − θ is called the bias of T ; if this difference is nonzero, then T is called biased.
Consistency
Consistency is about whether the point estimate stays close to the value when the parameter increases its size. The larger the sample size, the more accurate the estimate is. If a point estimator is consistent, its expected value and variance should be close to the true value of the parameter. An unbiased estimator is consistent if the limit of the variance of estimator T equals zero.
Efficiency
Let T1 and T2 be two unbiased estimators for the same parameter θ. The estimator T2 would be called more efficient than estimator T1 if Var(T2) < Var(T1), irrespective of the value of θ.[1] We can also say that the most efficient estimators are the ones with the least variability of outcomes. Therefore, if the estimator has smallest variance among sample to sample, it is both most efficient and unbiased. We extend the notion of efficiency by saying that estimator T2 is more efficient than estimator T1 (for the same parameter of interest), if the MSE(mean square error) of T2 is smaller than the MSE of T1.[1]
Generally, we must consider the distribution of the population when determining the efficiency of estimators. For example, in a normal distribution, the mean is considered more efficient than the median, but the same does not apply in asymmetrical, or skewed, distributions.
Sufficiency
In statistics, the job of a statistician is to interpret the data that they have collected and to draw statistically valid conclusion about the population under investigation. But in many cases the raw data, which are too numerous and too costly to store, are not suitable for this purpose. Therefore, the statistician would like to condense the data by computing some statistics and to base their analysis on these statistics so that there is no loss of relevant information in doing so, that is the statistician would like to choose those statistics which exhaust all information about the parameter, which is contained in the sample. We define sufficient statistics as follows: Let X =( X1, X2, ... ,Xn) be a random sample. A statistic T(X) is said to be sufficient for θ (or for the family of distribution) if the conditional distribution of X given T is free from θ.[2]
Types of point estimation
Bayesian point estimation
Bayesian inference is typically based on the posterior distribution. Many Bayesian point estimators are the posterior distribution's statistics of central tendency, e.g., its mean, median, or mode:
- Posterior mean, which minimizes the (posterior) risk (expected loss) for a squared-error loss function; in Bayesian estimation, the risk is defined in terms of the posterior distribution, as observed by Gauss.[3]
- Posterior median, which minimizes the posterior risk for the absolute-value loss function, as observed by Laplace.[3][4]
- maximum a posteriori (MAP), which finds a maximum of the posterior distribution; for a uniform prior probability, the MAP estimator coincides with the maximum-likelihood estimator;
The MAP estimator has good asymptotic properties, even for many difficult problems, on which the maximum-likelihood estimator has difficulties. For regular problems, where the maximum-likelihood estimator is consistent, the maximum-likelihood estimator ultimately agrees with the MAP estimator.[5][6][7] Bayesian estimators are admissible, by Wald's theorem.[6][8]
The Minimum Message Length (MML) point estimator is based in Bayesian information theory and is not so directly related to the posterior distribution.
Special cases of Bayesian filters are important:
Several methods of computational statistics have close connections with Bayesian analysis:
Methods of finding point estimates
Below are some commonly used methods of estimating unknown parameters which are expected to provide estimators having some of these important properties. In general, depending on the situation and the purpose of our study we apply any one of the methods that may be suitable among the methods of point estimation.
Method of maximum likelihood (MLE)
The method of maximum likelihood, due to R.A. Fisher, is the most important general method of estimation. This estimator method attempts to acquire unknown parameters that maximize the likelihood function. It uses a known model (ex. the normal distribution) and uses the values of parameters in the model that maximize a likelihood function to find the most suitable match for the data.[9]
Let X = (X1, X2, ... ,Xn) denote a random sample with joint p.d.f or p.m.f. f(x, θ) (θ may be a vector). The function f(x, θ), considered as a function of θ, is called the likelihood function. In this case, it is denoted by L(θ). The principle of maximum likelihood consists of choosing an estimate within the admissible range of θ, that maximizes the likelihood. This estimator is called the maximum likelihood estimate (MLE) of θ. In order to obtain the MLE of θ, we use the equation
dlogL(θ)/dθi=0, i = 1, 2, …, k. If θ is a vector, then partial derivatives are considered to get the likelihood equations.[2]
Method of moments (MOM)
The method of moments was introduced by K. Pearson and P. Chebyshev in 1887, and it is one of the oldest methods of estimation. This method is based on law of large numbers, which uses all the known facts about a population and apply those facts to a sample of the population by deriving equations that relate the population moments to the unknown parameters. We can then solve with the sample mean of the population moments.[10] However, due to the simplicity, this method is not always accurate and can be biased easily.
Let (X1, X2,…Xn) be a random sample from a population having p.d.f. (or p.m.f) f(x,θ), θ = (θ1, θ2, …, θk). The objective is to estimate the parameters θ1, θ2, ..., θk. Further, let the first k population moments about zero exist as explicit function of θ, i.e. μr = μr(θ1, θ2,…, θk), r = 1, 2, …, k. In the method of moments, we equate k sample moments with the corresponding population moments. Generally, the first k moments are taken because the errors due to sampling increase with the order of the moment. Thus, we get k equations μr(θ1, θ2,…, θk) = mr, r = 1, 2, …, k. Solving these equations we get the method of moment estimators (or estimates) as
mr = 1/n ΣXir.[2] See also generalized method of moments.
Method of least square
In the method of least square, we consider the estimation of parameters using some specified form of the expectation and second moment of the observations. For
fitting a curve of the form y = f( x, β0, β1, ,,,, βp) to the data (xi, yi), i = 1, 2,…n, we may use the method of least squares. This method consists of minimizing the
sum of squares.
When f(x, β0, β1, ,,,, βp) is a linear function of the parameters and the x-values are known, least square estimators will be best linear unbiased estimator (BLUE). Again, if we assume that the least square estimates are independently and identically normally distributed, then a linear estimator will be minimum-variance unbiased estimator (MVUE) for the entire class of unbiased estimators. See also minimum mean squared error (MMSE).[2]
Minimum-variance mean-unbiased estimator (MVUE)
The method of minimum-variance unbiased estimator minimizes the risk (expected loss) of the squared-error loss-function.
Median unbiased estimator
Median-unbiased estimator minimizes the risk of the absolute-error loss function.
Best linear unbiased estimator (BLUE)
Best linear unbiased estimator, also known as the Gauss–Markov theorem states that the ordinary least squares (OLS) estimator has the lowest sampling variance within the class of linear unbiased estimators, if the errors in the linear regression model are uncorrelated, have equal variances and expectation value of zero.[11]
Point estimate v.s. confidence interval estimate
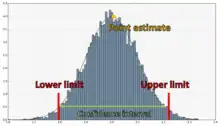
There are two major types of estimates: point estimate and confidence interval estimate. In the point estimate we try to choose a unique point in the parameter space which can reasonably be considered as the true value of the parameter. On the other hand, instead of unique estimate of the parameter, we are interested in constructing a family of sets that contain the true (unknown) parameter value with a specified probability. In many problems of statistical inference we are not interested only in estimating the parameter or testing some hypothesis concerning the parameter, we also want to get a lower or an upper bound or both, for the real-valued parameter. To do this, we need to construct a confidence interval.
Confidence interval describes how reliable an estimate is. We can calculate the upper and lower confidence limits of the intervals from the observed data. Suppose a dataset x1, . . . , xn is given, modeled as realization of random variables X1, . . . , Xn. Let θ be the parameter of interest, and γ a number between 0 and 1. If there exist sample statistics Ln = g(X1, . . . , Xn) and Un = h(X1, . . . , Xn) such that P(Ln < θ < Un) = γ for every value of θ, then (ln, un), where ln = g(x1, . . . , xn) and un = h(x1, . . . , xn), is called a 100γ% confidence interval for θ. The number γ is called the confidence level.[1] In general, with a normally-distributed sample mean, Ẋ, and with a known value for the standard deviation, σ, a 100(1-α)% confidence interval for the true μ is formed by taking Ẋ ± e, with e = z1-α/2(σ/n1/2), where z1-α/2 is the 100(1-α/2)% cumulative value of the standard normal curve, and n is the number of data values in that column. For example, z1-α/2 equals 1.96 for 95% confidence.[12]
Here two limits are computed from the set of observations, say ln and un and it is claimed with a certain degree of confidence (measured in probabilistic terms) that the true value of γ lies between ln and un. Thus we get an interval (ln and un) which we expect would include the true value of γ(θ). So this type of estimation is called confidence interval estimation.[2] This estimation provides a range of values which the parameter is expected to lie. It generally gives more information than point estimates and are preferred when making inferences. In some way, we can say that point estimation is the opposite of interval estimation.
See also
References
- 1 2 3 4 5 A Modern Introduction to Probability and Statistics. F.M. Dekking, C. Kraaikamp, H.P. Lopuhaa, L.E. Meester. 2005.
- 1 2 3 4 5 Estimation and Inferential Statistics. Pradip Kumar Sahu, Santi Ranjan Pal, Ajit Kumar Das. 2015.
- 1 2 Dodge, Yadolah, ed. (1987). Statistical data analysis based on the L1-norm and related methods: Papers from the First International Conference held at Neuchâtel, August 31–September 4, 1987. North-Holland Publishing.
- ↑ Jaynes, E. T. (2007). Probability Theory: The logic of science (5. print. ed.). Cambridge University Press. p. 172. ISBN 978-0-521-59271-0.
- ↑ Ferguson, Thomas S. (1996). A Course in Large Sample Theory. Chapman & Hall. ISBN 0-412-04371-8.
- 1 2 Le Cam, Lucien (1986). Asymptotic Methods in Statistical Decision Theory. Springer-Verlag. ISBN 0-387-96307-3.
- ↑ Ferguson, Thomas S. (1982). "An inconsistent maximum likelihood estimate". Journal of the American Statistical Association. 77 (380): 831–834. doi:10.1080/01621459.1982.10477894. JSTOR 2287314.
- ↑ Lehmann, E. L.; Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer. ISBN 0-387-98502-6.
- ↑ Categorical Data Analysis. John Wiley and Sons, New York: Agresti A. 1990.
- ↑ The Concise Encyclopedia of Statistics. Springer: Dodge, Y. 2008.
- ↑ Best Linear Unbiased Estimation and Prediction. New York: John Wiley & Sons: Theil Henri. 1971.
- ↑ Experimental Design – With Applications in Management, Engineering, and the Sciences. Springer: Paul D. Berger, Robert E. Maurer, Giovana B. Celli. 2019.
Further reading
- Bickel, Peter J. & Doksum, Kjell A. (2001). Mathematical Statistics: Basic and Selected Topics. Vol. I (Second (updated printing 2007) ed.). Pearson Prentice-Hall.
- Liese, Friedrich & Miescke, Klaus-J. (2008). Statistical Decision Theory: Estimation, Testing, and Selection. Springer.