In theoretical computer science, communication complexity studies the amount of communication required to solve a problem when the input to the problem is distributed among two or more parties. The study of communication complexity was first introduced by Andrew Yao in 1979, while studying the problem of computation distributed among several machines.[1] The problem is usually stated as follows: two parties (traditionally called Alice and Bob) each receive a (potentially different) -bit string and . The goal is for Alice to compute the value of a certain function, , that depends on both and , with the least amount of communication between them.




While Alice and Bob can always succeed by having Bob send his whole -bit string to Alice (who then computes the function ), the idea here is to find clever ways of calculating with fewer than bits of communication. Note that, unlike in computational complexity theory, communication complexity is not concerned with the amount of computation performed by Alice or Bob, or the size of the memory used, as we generally assume nothing about the computational power of either Alice or Bob.

This abstract problem with two parties (called two-party communication complexity), and its general form with more than two parties, is relevant in many contexts. In VLSI circuit design, for example, one seeks to minimize energy used by decreasing the amount of electric signals passed between the different components during a distributed computation. The problem is also relevant in the study of data structures and in the optimization of computer networks. For surveys of the field, see the textbooks by Rao & Yehudayoff (2020) and Kushilevitz & Nisan (2006).
Formal definition
Let where we assume in the typical case that and . Alice holds an -bit string while Bob holds an -bit string . By communicating to each other one bit at a time (adopting some communication protocol which is agreed upon in advance), Alice and Bob wish to compute the value of such that at least one party knows the value at the end of the communication. At this point the answer can be communicated back so that at the cost of one extra bit, both parties will know the answer. The worst case communication complexity of this communication problem of computing , denoted as , is then defined to be






- minimum number of bits exchanged between Alice and Bob in the worst case.

As observed above, for any function , we have . Using the above definition, it is useful to think of the function as a matrix (called the input matrix or communication matrix) where the rows are indexed by and columns by . The entries of the matrix are . Initially both Alice and Bob have a copy of the entire matrix (assuming the function is known to both parties). Then, the problem of computing the function value can be rephrased as "zeroing-in" on the corresponding matrix entry. This problem can be solved if either Alice or Bob knows both and . At the start of communication, the number of choices for the value of the function on the inputs is the size of matrix, i.e. . Then, as and when each party communicates a bit to the other, the number of choices for the answer reduces as this eliminates a set of rows/columns resulting in a submatrix of .





More formally, a set is called a (combinatorial) rectangle if whenever and then . Equivalently, is a combinatorial rectangle if it can be expressed as for some and . Consider the case when bits are already exchanged between the parties. Now, for a particular , let us define a matrix











Then, , and it is not hard to show that is a combinatorial rectangle in .


Example:

We consider the case where Alice and Bob try to determine whether or not their input strings are equal. Formally, define the Equality function, denoted , by if . As we demonstrate below, any deterministic communication protocol solving requires bits of communication in the worst case. As a warm-up example, consider the simple case of . The equality function in this case can be represented by the matrix below. The rows represent all the possibilities of , the columns those of .




| EQ | 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
|---|---|---|---|---|---|---|---|---|
| 000 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 001 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 010 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 011 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 100 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 101 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 110 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 111 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
In this table, the function only evaluates to 1 when equals (i.e., on the diagonal). It is also fairly easy to see how communicating a single bit divides someone's possibilities in half. When the first bit of is 1, consider only half of the columns (where can equal 100, 101, 110, or 111).
Theorem:

Proof. Assume that . This means that there exists such that and have the same communication transcript . Since this transcript defines a rectangle, must also be 1. By definition and we know that equality is only true for when . This yields a contradiction.








This technique of proving deterministic communication lower bounds is called the fooling set technique.[2]
Randomized communication complexity
In the above definition, we are concerned with the number of bits that must be deterministically transmitted between two parties. If both the parties are given access to a random number generator, can they determine the value of with much less information exchanged? Yao, in his seminal paper[1] answers this question by defining randomized communication complexity.
A randomized protocol for a function has two-sided error.
![{\displaystyle \Pr[R(x,y)=0]>{\frac {2}{3}},{\textrm {if}}\,f(x,y)=0}](../I/39f5743f91ce78c002e9e86e66c8a3a30a0a5f50.svg)
![{\displaystyle \Pr[R(x,y)=1]>{\frac {2}{3}},{\textrm {if}}\,f(x,y)=1}](../I/b4240e87e04d8248ed6eaaf08470ce1d1ce95826.svg)
A randomized protocol is a deterministic protocol that uses an extra random string in addition to its normal input. There are two models for this: a public string is a random string that is known by both parties beforehand, while a private string is generated by one party and must be communicated to the other party. A theorem presented below shows that any public string protocol can be simulated by a private string protocol that uses O(log n) additional bits compared to the original.
Note that in the probability inequalities above, the outcome of the protocol is understood to depend only on the random string; both strings x and y remain fixed. In other words, if R(x,y) yields g(x,y,r) when using random string r, then g(x,y,r) = f(x,y) for at least 2/3 of all choices for the string r.
The randomized complexity is simply defined as the number of bits exchanged in such a protocol.
Note that it is also possible to define a randomized protocol with one-sided error, and the complexity is defined similarly.
Example: EQ
Returning to the previous example of EQ, if certainty is not required, Alice and Bob can check for equality using only messages. Consider the following protocol: Assume that Alice and Bob both have access to the same random string . Alice computes and sends this bit (call it b) to Bob. (The is the dot product in GF(2).) Then Bob compares b to . If they are the same, then Bob accepts, saying x equals y. Otherwise, he rejects.





Clearly, if , then , so . If x does not equal y, it is still possible that , which would give Bob the wrong answer. How does this happen?

![Prob_{z}[Accept]=1](../I/78dbcb0e425212f1f5793af92475e1c3d6099683.svg)
If x and y are not equal, they must differ in some locations:

Where x and y agree, so those terms affect the dot products equally. We can safely ignore those terms and look only at where x and y differ. Furthermore, we can swap the bits and without changing whether or not the dot products are equal. This means we can swap bits so that x contains only zeros and y contains only ones:




Note that and . Now, the question becomes: for some random string , what is the probability that ? Since each is equally likely to be 0 or 1, this probability is just . Thus, when x does not equal y, . The algorithm can be repeated many times to increase its accuracy. This fits the requirements for a randomized communication algorithm.






![Prob_{z}[Accept]=1/2](../I/28779b6e5046f8b693569b781296fc8b7aa0d4fa.svg)
This shows that if Alice and Bob share a random string of length n, they can send one bit to each other to compute . In the next section, it is shown that Alice and Bob can exchange only bits that are as good as sharing a random string of length n. Once that is shown, it follows that EQ can be computed in messages.

Example: GH
For yet another example of randomized communication complexity, we turn to an example known as the gap-Hamming problem (abbreviated GH). Formally, Alice and Bob both maintain binary messages, and would like to determine if the strings are very similar or if they are not very similar. In particular, they would like to find a communication protocol requiring the transmission of as few bits as possible to compute the following partial Boolean function,


Clearly, they must communicate all their bits if the protocol is to be deterministic (this is because, if there is a deterministic, strict subset of indices that Alice and Bob relay to one another, then imagine having a pair of strings that on that set disagree in positions. If another disagreement occurs in any position that is not relayed, then this affects the result of , and hence would result in an incorrect procedure.


A natural question one then asks is, if we're permitted to err of the time (over random instances drawn uniformly at random from ), then can we get away with a protocol with fewer bits? It turns out that the answer somewhat surprisingly is no, due to a result of Chakrabarti and Regev in 2012: they show that for random instances, any procedure which is correct at least of the time must send bits worth of communication, which is to say essentially all of them.





Public coins versus private coins
Creating random protocols becomes easier when both parties have access to the same random string, known as a shared string protocol. However, even in cases where the two parties do not share a random string, it is still possible to use private string protocols with only a small communication cost. Any shared string random protocol using any number of random string can be simulated by a private string protocol that uses an extra O(log n) bits.
Intuitively, we can find some set of strings that has enough randomness in it to run the random protocol with only a small increase in error. This set can be shared beforehand, and instead of drawing a random string, Alice and Bob need only agree on which string to choose from the shared set. This set is small enough that the choice can be communicated efficiently. A formal proof follows.
Consider some random protocol P with a maximum error rate of 0.1. Let be strings of length n, numbered . Given such an , define a new protocol which randomly picks some and then runs P using as the shared random string. It takes O(log 100n) = O(log n) bits to communicate the choice of .




Let us define and to be the probabilities that and compute the correct value for the input .




For a fixed , we can use Hoeffding's inequality to get the following equation:
![\Pr _{R}[|p'_{R}(x,y)-p(x,y)|\geq 0.1]\leq 2\exp(-2(0.1)^{2}\cdot 100n)<2^{-2n}](../I/45f8000f9397f6ab452081c1b118ba696e24e5d0.svg)
Thus when we don't have fixed:
![{\displaystyle \Pr _{R}[\exists (x,y):\ |p'_{R}(x,y)-p(x,y)|\geq 0.1]\leq \sum _{(x,y)}\Pr _{R}[|p'_{R}(x,y)-p(x,y)|\geq 0.1]<\sum _{(x,y)}2^{-2n}=1}](../I/8fe4b3f6e899f3718094a415abc5c37bbef639b1.svg)
The last equality above holds because there are different pairs . Since the probability does not equal 1, there is some so that for all :


Since has at most 0.1 error probability, can have at most 0.2 error probability.

Collapse of Randomized Communication Complexity
Let's say we additionally allow Alice and Bob to share some resource, for example a pair of entangle particles. Using that ressource, Alice and Bob can correlate their information and thus try to 'collapse' (or 'trivialize') communication complexity in the following sense.
Definition. A resource is said to be "collapsing" if, using that resource , only one bit of classical communication is enough for Alice to know the evaluation in the worst case scenario for any Boolean function .
The surprising fact of a collapse of communication complexity is that the function can have arbitrarily large entry size, but still the number of communication bit is constant to a single one.
Some resources are shown to be non-collapsing, such as quantum correlations [3] or more generally almost-quantum correlations,[4] whereas on the contrary some other resources are shown to collapse randomized communication complexity, such as the PR-box,[5] or some noisy PR-boxes satisfying some conditions.[6][7][8]
Distributional Complexity
One approach to studying randomized communication complexity is through distributional complexity.
Given a joint distribution on the inputs of both players, the corresponding distributional complexity of a function is the minimum cost of a deterministic protocol such that , where the inputs are sampled according to .

![{\displaystyle \Pr[f(x,y)=R(x,y)]\geq 2/3}](../I/a079ec0ea681763e9c426815d6a8ff71b428698e.svg)
Yao's minimax principle[9] (a special case of von Neumann's minimax theorem) states that the randomized communication complexity of a function equals its maximum distributional complexity, where the maximum is taken over all joint distributions of the inputs (not necessarily product distributions!).
Yao's principle can be used to prove lower bounds on the randomized communication complexity of a function: design the appropriate joint distribution, and prove a lower bound on the distributional complexity. Since distributional complexity concerns deterministic protocols, this could be easier than proving a lower bound on randomized protocols directly.
As an example, let us consider the disjointness function DISJ: each of the inputs is interpreted as a subset of , and DISJ(x,y)=1 if the two sets are disjoint. Razborov[10] proved an lower bound on the randomized communication complexity by considering the following distribution: with probability 3/4, sample two random disjoint sets of size , and with probability 1/4, sample two random sets of size with a unique intersection.


Information Complexity
A powerful approach to the study of distributional complexity is information complexity. Initiated by Bar-Yossef, Jayram, Kumar and Sivakumar,[11] the approach was codified in work of Barak, Braverman, Chen and Rao[12] and by Braverman and Rao.[13]
The (internal) information complexity of a (possibly randomized) protocol R with respect to a distribution μ is defined as follows. Let be random inputs sampled according to μ, and let Π be the transcript of R when run on the inputs . The information complexity of the protocol is



where I denotes conditional mutual information. The first summand measures the amount of information that Alice learns about Bob's input from the transcript, and the second measures the amount of information that Bob learns about Alice's input.
The ε-error information complexity of a function f with respect to a distribution μ is the infimal information complexity of a protocol for f whose error (with respect to μ) is at most ε.
Braverman and Rao proved that information equals amortized communication. This means that the cost for solving n independent copies of f is roughly n times the information complexity of f. This is analogous to the well-known interpretation of Shannon entropy as the amortized bit-length required to transmit data from a given information source. Braverman and Rao's proof uses a technique known as "protocol compression", in which an information-efficient protocol is "compressed" into a communication-efficient protocol.
The techniques of information complexity enable the computation of the exact (up to first order) communication complexity of set disjointness to be .[14]

Information complexity techniques have also been used to analyze extended formulations, proving an essentially optimal lower bound on the complexity of algorithms based on linear programming which approximately solve the maximum clique problem.[15]
Omri Weinstein's 2015 survey[16] surveys the subject.
Quantum communication complexity
Quantum communication complexity tries to quantify the communication reduction possible by using quantum effects during a distributed computation.
At least three quantum generalizations of communication complexity have been proposed; for a survey see the suggested text by G. Brassard.
The first one is the qubit-communication model, where the parties can use quantum communication instead of classical communication, for example by exchanging photons through an optical fiber.
In a second model the communication is still performed with classical bits, but the parties are allowed to manipulate an unlimited supply of quantum entangled states as part of their protocols. By doing measurements on their entangled states, the parties can save on classical communication during a distributed computation.
The third model involves access to previously shared entanglement in addition to qubit communication, and is the least explored of the three quantum models.
Nondeterministic communication complexity
In nondeterministic communication complexity, Alice and Bob have access to an oracle. After receiving the oracle's word, the parties communicate to deduce . The nondeterministic communication complexity is then the maximum over all pairs over the sum of number of bits exchanged and the coding length of the oracle word.
Viewed differently, this amounts to covering all 1-entries of the 0/1-matrix by combinatorial 1-rectangles (i.e., non-contiguous, non-convex submatrices, whose entries are all one (see Kushilevitz and Nisan or Dietzfelbinger et al.)). The nondeterministic communication complexity is the binary logarithm of the rectangle covering number of the matrix: the minimum number of combinatorial 1-rectangles required to cover all 1-entries of the matrix, without covering any 0-entries.
Nondeterministic communication complexity occurs as a means to obtaining lower bounds for deterministic communication complexity (see Dietzfelbinger et al.), but also in the theory of nonnegative matrices, where it gives a lower bound on the nonnegative rank of a nonnegative matrix.[17]
Unbounded-error communication complexity
In the unbounded-error setting, Alice and Bob have access to a private coin and their own inputs . In this setting, Alice succeeds if she responds with the correct value of with probability strictly greater than 1/2. In other words, if Alice's responses have any non-zero correlation to the true value of , then the protocol is considered valid.
Note that the requirement that the coin is private is essential. In particular, if the number of public bits shared between Alice and Bob are not counted against the communication complexity, it is easy to argue that computing any function has communication complexity.[18] On the other hand, both models are equivalent if the number of public bits used by Alice and Bob is counted against the protocol's total communication.[19]

Though subtle, lower bounds on this model are extremely strong. More specifically, it is clear that any bound on problems of this class immediately imply equivalent bounds on problems in the deterministic model and the private and public coin models, but such bounds also hold immediately for nondeterministic communication models and quantum communication models.[20]
Forster[21] was the first to prove explicit lower bounds for this class, showing that computing the inner product requires at least bits of communication, though an earlier result of Alon, Frankl, and Rödl proved that the communication complexity for almost all Boolean functions is .[22]


Lifting
Lifting is a general technique in complexity theory in which a lower bound on a simple measure of complexity is "lifted" to a lower bound on a more difficult measure.
This technique was pioneered in the context of communication complexity by Raz and McKenzie,[23] who proved the first query-to-communication lifting theorem, and used the result to separate the monotone NC hierarchy.
Given a function and a gadget , their composition is defined as follows:




In words, is partitioned into blocks of length , and is partitioned into blocks of length . The gadget is applied times on the blocks, and the outputs are fed into . Diagrammatically:


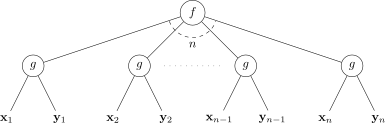
In this diagram, each of the inputs is a bits long, and each of the inputs is b bits long.


A decision tree of depth for can be translated to a communication protocol whose cost is : each time the tree queries a bit, the corresponding value of is computed using an optimal protocol for . Raz and McKenzie showed that this is optimal up to a constant factor when is the so-called "indexing gadget", in which has length (for a large enough constant c), has length , and is the -th bit of .






The proof of the Raz–McKenzie lifting theorem uses the method of simulation, in which a protocol for the composed function is used to generate a decision tree for . Göös, Pitassi and Watson[24] gave an exposition of the original proof. Since then, several works have proved similar theorems with different gadgets, such as inner product.[25] The smallest gadget which can be handled is the indexing gadget with .[26] Göös, Pitassi and Watson extended the Raz–McKenzie technique to randomized protocols.[27]


A simple modification of the Raz–McKenzie lifting theorem gives a lower bound of on the logarithm of the size of a protocol tree for computing , where is the depth of the optimal decision tree for . Garg, Göös, Kamath and Sokolov extended this to the DAG-like setting,[28] and used their result to obtain monotone circuit lower bounds. The same technique has also yielded applications to proof complexity.[29]
A different type of lifting is exemplified by Sherstov's pattern matrix method,[30] which gives a lower bound on the quantum communication complexity of , where g is a modified indexing gadget, in terms of the approximate degree of f. The approximate degree of a Boolean function is the minimal degree of a polynomial which approximates the function on all Boolean points up to an additive error of 1/3.
In contrast to the Raz–McKenzie proof which uses the method of simulation, Sherstov's proof takes a dual witness to the approximate degree of f and gives a lower bound on the quantum query complexity of using the generalized discrepancy method. The dual witness for the approximate degree of f is a lower bound witness for the approximate degree obtained via LP duality. This dual witness is massaged into other objects constituting data for the generalized discrepancy method.
Another example of this approach is the work of Pitassi and Robere,[31] in which an algebraic gap is lifted to a lower bound on Razborov's rank measure. The result is a strongly exponential lower bound on the monotone circuit complexity of an explicit function, obtained via the Karchmer–Wigderson characterization[32] of monotone circuit size in terms of communication complexity.
Open problems
Considering a 0 or 1 input matrix , the minimum number of bits exchanged to compute deterministically in the worst case, , is known to be bounded from below by the logarithm of the rank of the matrix . The log rank conjecture proposes that the communication complexity, , is bounded from above by a constant power of the logarithm of the rank of . Since D(f) is bounded from above and below by polynomials of log rank, we can say D(f) is polynomially related to log rank. Since the rank of a matrix is polynomial time computable in the size of the matrix, such an upper bound would allow the matrix's communication complexity to be approximated in polynomial time. Note, however, that the size of the matrix itself is exponential in the size of the input.
![M_{f}=[f(x,y)]_{x,y\in \{0,1\}^{n}}](../I/8ec0cc3d5f48abac95dcfd8060acefcf11884876.svg)


For a randomized protocol, the number of bits exchanged in the worst case, R(f), was conjectured to be polynomially related to the following formula:

Such log rank conjectures are valuable because they reduce the question of a matrix's communication complexity to a question of linearly independent rows (columns) of the matrix. This particular version, called the Log-Approximate-Rank Conjecture, was recently refuted by Chattopadhyay, Mande and Sherif (2019)[33] using a surprisingly simple counter-example. This reveals that the essence of the communication complexity problem, for example in the EQ case above, is figuring out where in the matrix the inputs are, in order to find out if they're equivalent.
Applications
Lower bounds in communication complexity can be used to prove lower bounds in decision tree complexity, VLSI circuits, data structures, streaming algorithms, space–time tradeoffs for Turing machines and more.[2]
Conitzer and Sandholm[34] studied the communication complexity of some common voting rules, which are essential in political and non political organizations. Compilation complexity is a closely related notion, which can be seen as a single-round communication complexity.
See also
Notes
- 1 2 Yao, A. C. (1979), "Some Complexity Questions Related to Distributive Computing", Proc. Of 11th STOC, 14: 209–213
- 1 2 Kushilevitz, Eyal; Nisan, Noam (1997). Communication Complexity. Cambridge University Press. ISBN 978-0-521-56067-2.
- ↑ R. Cleve, W. van Dam, M. Nielsen, and A. Tapp, Quantum Computing and Quantum Communications (Springer Berlin Heidelberg, Berlin, Heidelberg, 1999) pp. 61–74.
- ↑ M. Navascués, Y. Guryanova, M. J. Hoban, and A. Acín, Nature Communications 6, 6288 (2015).
- ↑ W. van Dam, Nonlocality & Communication Complexity, Ph.d. thesis, University of Oxford (1999).
- ↑ G. Brassard, H. Buhrman, N. Linden, A. A. M ́ethot, A. Tapp, and F. Unger, Phys. Rev. Lett. 96, 250401 (2006).
- ↑ N. Brunner and P. Skrzypczyk, Phys. Rev. Lett. 102, 160403 (2009).
- ↑ P. Botteron, A. Broadbent and M.-O. Proulx, arXiv:2302.00488.
- ↑ Yao, Andrew Chi-Chih (1977). "Probabilistic computations: Toward a unified measure of complexity". 18th Annual Symposium on Foundations of Computer Science (sfcs 1977). IEEE. doi:10.1109/SFCS.1977.24. ISSN 0272-5428.
- ↑ Razborov, Alexander (1992). "On the distributional complexity of disjointness". Theoretical Computer Science. 106: 385–390. doi:10.1016/0304-3975(92)90260-M. Retrieved 1 December 2023.
- ↑ Bar-Yossef, Ziv; Jayram, T. S.; Kumar, Ravi; Sivakumar, D. (2004). "An information statistics approach to data stream and communication complexity" (PDF). Journal of Computer and System Sciences. 68: 702–732. doi:10.1016/j.jcss.2003.11.006. Retrieved 1 December 2023.
- ↑ Barak, Boaz; Braverman, Mark; Chen, Xi; Rao, Anup (2013). "How to Compress Interactive Communication" (PDF). SIAM Journal on Computing. 42 (3): 1327–1363. doi:10.1137/100811969.
- ↑ Braverman, Mark; Rao, Anup (2014). "Information equals amortized communication" (PDF). IEEE Transactions on Information Theory. 60 (10): 6058–6069. doi:10.1109/TIT.2014.2347282.
- ↑ Braverman, Mark; Garg, Ankit; Pankratov, Denis; Weinstein, Omri (June 2013). STOC '13: Proceedings of the forty-fifth annual ACM symposium on Theory of Computing. Palo Alto, CA: ACM. pp. 151–160. doi:10.1145/2488608.2488628.
- ↑ Braverman, Mark; Moitra, Ankur (1 June 2013). "An information complexity approach to extended formulations". STOC '13: Proceedings of the forty-fifth annual ACM symposium on Theory of Computing. Palo Alto, CA: ACM. pp. 161–170. doi:10.1145/2488608.2488629.
- ↑ Weinstein, Omri (June 2015). "Information Complexity and the Quest for Interactive Compression". ACM SIGACT News. 46 (2): 41–64. doi:10.1145/2789149.2789161. Retrieved 1 December 2023.
- ↑ Yannakakis, M. (1991). "Expressing combinatorial optimization problems by linear programs". J. Comput. Syst. Sci. 43 (3): 441–466. doi:10.1016/0022-0000(91)90024-y.
- ↑ Lovett, Shachar, CSE 291: Communication Complexity, Winter 2019 Unbounded-error protocols (PDF), retrieved June 9, 2019
- ↑ Göös, Mika; Pitassi, Toniann; Watson, Thomas (2018-06-01). "The Landscape of Communication Complexity Classes". Computational Complexity. 27 (2): 245–304. doi:10.1007/s00037-018-0166-6. ISSN 1420-8954. S2CID 4333231.
- ↑ Sherstov, Alexander A. (October 2008). "The Unbounded-Error Communication Complexity of Symmetric Functions". 2008 49th Annual IEEE Symposium on Foundations of Computer Science. pp. 384–393. doi:10.1109/focs.2008.20. ISBN 978-0-7695-3436-7. S2CID 9072527.
- ↑ Forster, Jürgen (2002). "A linear lower bound on the unbounded error probabilistic communication complexity". Journal of Computer and System Sciences. 65 (4): 612–625. doi:10.1016/S0022-0000(02)00019-3.
- ↑ Alon, N.; Frankl, P.; Rodl, V. (October 1985). "Geometrical realization of set systems and probabilistic communication complexity". 26th Annual Symposium on Foundations of Computer Science (SFCS 1985). Portland, OR, USA: IEEE. pp. 277–280. CiteSeerX 10.1.1.300.9711. doi:10.1109/SFCS.1985.30. ISBN 9780818606441. S2CID 8416636.
- ↑ Raz, Ran; McKenzie, Pierre (1999). "Separation of the Monotone NC Hierarchy". Combinatorica. 19: 403–435. doi:10.1007/s004930050062.
- ↑ Göös, Mika; Pitassi, Toniann; Watson, Thomas (2018). "Deterministic communication vs. partition number". SIAM Journal on Computing. 74 (6): 2435–2450. doi:10.1137/16M1059369.
- ↑ Chattopadhyay, Arkadev; Koucký, Michal; Loff, Bruno; Mukhopadhyay, Sagnik (2019). "Simulation theorems via pseudo-random properties". Computational Complexity. 28 (4): 617–659. arXiv:1704.06807. doi:10.1007/s00037-019-00190-7.
- ↑ Lovett, Shachar; Meka, Raghu; Mertz, Ian; Pitassi, Toniann; Zhang, Jiapeng (200). "Lifting with Sunflowers" (PDF). 13th Innovations in Theoretical Computer Science Conference (ITCS 2022). Vol. 215. Leibniz International Proceedings in Informatics (LIPIcs). pp. 104:1-104:24. doi:10.4230/LIPIcs.ITCS.2022.104.
- ↑ Göös, Mika; Pitassi, Toniann; Watson, Thomas (2017). "Query-to-Communication Lifting for BPP". 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS). Berkeley, CA: IEEE. arXiv:1703.07666. doi:10.1109/FOCS.2017.21.
- ↑ Garg, Ankit; Göös, Mika; Kamath, Pritish; Sokolov, Dmitry (2020). "Monotone Circuit Lower Bounds from Resolution". Theory of Computing. 16: 13:1–13:30. doi:10.4086/toc.2020.v016a013.
- ↑ de Rezende, Susanna; Meir, Or; Nordström, Jakob; Pitassi, Toniann; Robere, Robere; Vinyals, Marc (2020). "Lifting with Simple Gadgets and Applications to Circuit and Proof Complexity". 2020 IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS). Virtual conference: IEEE. pp. 24–30. arXiv:2001.02144. doi:10.1109/FOCS46700.2020.00011.
- ↑ Sherstov, Alexander (2011). "The pattern matrix method". SIAM Journal on Computing. 40 (6): 1969–2000. doi:10.1137/080733644.
- ↑ Pitassi, Toniann; Robere, Robert (2017). "Strongly Exponential Lower Bounds for Monotone Computation" (PDF). STOC 2017: Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing. Montreal: ACM. pp. 1246–1255. doi:10.1145/3055399.3055478.
- ↑ Karchmer, Mauricio; Wigderson, Avi (1990). "Monotone circuits for connectivity require super-logarithmic depth" (PDF). SIAM Journal on Discrete Mathematics. 3 (2): 255–265. doi:10.1137/0403021.
- ↑ Chattopadhyay, Arkadev; Mande, Nikhil S.; Sherif, Suhail (2019). "The Log-Approximate-Rank Conjecture is False". 2019, Proceeding of the 51st Annual ACM Symposium on Theory of Computing: 42-53.https://doi.org/10.1145/3313276.3316353
- ↑ Conitzer, Vincent; Sandholm, Tuomas (2005-06-05). "Communication complexity of common voting rules". Proceedings of the 6th ACM conference on Electronic commerce. EC '05. New York, NY, USA: Association for Computing Machinery: 78–87. doi:10.1145/1064009.1064018. ISBN 978-1-59593-049-1.
References
- Rao, Anup; Yehudayoff, Amir (2020). Communication complexity and applications. Cambridge: Cambridge University Press. ISBN 9781108671644.
- Kushilevitz, Eyal; Nisan, Noam (2006). Communication complexity. Cambridge: Cambridge University Press. ISBN 978-0-521-02983-4. OCLC 70764786.
- Brassard, G. Quantum communication complexity: a survey. https://arxiv.org/abs/quant-ph/0101005
- Dietzfelbinger, M., J. Hromkovic, J., and G. Schnitger, "A comparison of two lower-bound methods for communication complexity", Theoret. Comput. Sci. 168, 1996. 39-51.
- Raz, Ran. "Circuit and Communication Complexity." In Computational Complexity Theory. Steven Rudich and Avi Wigderson, eds. American Mathematical Society Institute for Advanced Study, 2004. 129-137.
- A. C. Yao, "Some Complexity Questions Related to Distributed Computing", Proc. of 11th STOC, pp. 209–213, 1979. 14
- I. Newman, Private vs. Common Random Bits in Communication Complexity, Information Processing Letters 39, 1991, pp. 67–71.