
The Aztec Code is a matrix code invented by Andrew Longacre, Jr. and Robert Hussey in 1995.[1] The code was published by AIM, Inc. in 1997. Although the Aztec Code was patented, that patent was officially made public domain.[2] The Aztec Code is also published as ISO/IEC 24778:2008 standard. Named after the resemblance of the central finder pattern to an Aztec pyramid, Aztec Code has the potential to use less space than other matrix barcodes because it does not require a surrounding blank "quiet zone".
Structure
The symbol is built on a square grid with a bull's-eye pattern at its centre for locating the code. Data is encoded in concentric square rings around the bull's-eye pattern. The central bull's-eye is 9×9 or 13×13 pixels, and one row of pixels around that encodes basic coding parameters, producing a "core" of 11×11 or 15×15 squares. Data is added in "layers", each one containing two rings of pixels, giving total sizes of 15×15, 19×19, 23×23, etc.
The corners of the core include orientation marks, allowing the code to be read if rotated or reflected. Decoding begins at the corner with three black pixels, and proceeds clockwise to the corners with two, one, and zero black pixels. The variable pixels in the central core encode the size, so it is not necessary to mark the boundary of the code with a blank "quiet zone", although some barcode readers require one.
 The core of the compact Aztec code (red ascending diagonal hatching), showing the central bull's-eye, the four orientation marks (blue diagonal cross-hatching), and space for 28 bits (7 bits per side) of coding information (green horizontal hatching). The first ring of data begins outside that (grey descending diagonal hatching).
The core of the compact Aztec code (red ascending diagonal hatching), showing the central bull's-eye, the four orientation marks (blue diagonal cross-hatching), and space for 28 bits (7 bits per side) of coding information (green horizontal hatching). The first ring of data begins outside that (grey descending diagonal hatching). The core of the full Aztec code. 40 bits are available between the orientation marks for encoding parameters.
The core of the full Aztec code. 40 bits are available between the orientation marks for encoding parameters.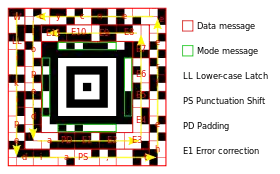 Message data is placed in a spiral pattern around the core. The mode message begins "01011100", indicating 01₂+1 = 2 layers, and 011100₂+1 = 29 data codewords (of 6 bits each).
Message data is placed in a spiral pattern around the core. The mode message begins "01011100", indicating 01₂+1 = 2 layers, and 011100₂+1 = 29 data codewords (of 6 bits each).
The compact Aztec code core may be surrounded by 1 to 4 layers, producing symbols from 15×15 (room for 13 digits or 12 letters) through 27×27. There is additionally a special 11×11 "rune" that encodes one byte of information. The full core supports up to 32 layers, 151×151 pixels, which can encode 3832 digits, 3067 letters, or 1914 bytes of data.
Whatever part of the symbol is not used for the basic data is used for Reed–Solomon error correction, and the split is completely configurable, between limits of 1 data word, and 3 check words. The recommended number of check words is 23% of symbol capacity plus 3 codewords.[3]
Aztec Code is supposed to produce readable codes with various printer technologies. It is also well suited for displays of cell phones and other mobile devices.
Encoding
The encoding process consists of the following steps:
- Converting the source message to a string of bits
- Computing the necessary symbol size and mode message, which determines the Reed–Solomon codeword size
- Bit-stuffing the message into Reed–Solomon codewords
- Padding the message to a codeword boundary
- Appending check codewords
- Arranging the complete message in a spiral around the core
All conversion between bits strings and other forms is performed according to the big-endian (most significant bit first) convention.
Character set
All 8-bit values can be encoded, plus two escape codes:
- FNC1, an escape symbol used to mark the presence of an application identifier, in the same way as in the GS1-128 standard.
- ECI, an escape followed by a 6-digit Extended Channel Interpretation code, which specifies the character set used to interpret the following bytes.
By default, codes 0–127 are interpreted according to ANSI X3.4 (ASCII), and 128–255 are interpreted according to ISO/IEC 8859-1: Latin Alphabet No. 1. This corresponds to ECI 000003.
Bytes are translated into 4- and 5-bit codes, based on a current decoding mode, with shift and latch codes for changing modes. Byte values not available this way may be encoded using a general "binary shift" code, which is followed by a length and a number of 8-bit codes.
For changing modes, a shift affects only the interpretation of the single following code, while a latch affects all following codes. Most modes use 5-bit codes, but Digit mode uses 4-bit codes.
| Code | Mode | Code | Mode | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Upper | Lower | Mixed | Punct | Digit | Upper | Lower | Mixed | Punct | |||
| 0 | P/S | P/S | P/S | FLG(n) | P/S | 16 | O | o | ^\ | + | |
| 1 | SP | SP | SP | CR | SP | 17 | P | p | ^] | , | |
| 2 | A | a | ^A | CR LF | 0 | 18 | Q | q | ^^ | - | |
| 3 | B | b | ^B | . SP | 1 | 19 | R | r | ^_ | . | |
| 4 | C | c | ^C | , SP | 2 | 20 | S | s | @ | / | |
| 5 | D | d | ^D | : SP | 3 | 21 | T | t | \ | : | |
| 6 | E | e | ^E | ! | 4 | 22 | U | u | ^ | ; | |
| 7 | F | f | ^F | " | 5 | 23 | V | v | _ | < | |
| 8 | G | g | ^G | # | 6 | 24 | W | w | ` | = | |
| 9 | H | h | ^H | $ | 7 | 25 | X | x | | | > | |
| 10 | I | i | ^I | % | 8 | 26 | Y | y | ~ | ? | |
| 11 | J | j | ^J | & | 9 | 27 | Z | z | ^? | [ | |
| 12 | K | k | ^K | ' | , | 28 | L/L | U/S | L/L | ] | |
| 13 | L | l | ^L | ( | . | 29 | M/L | M/L | U/L | { | |
| 14 | M | m | ^M | ) | U/L | 30 | D/L | D/L | P/L | } | |
| 15 | N | n | ^[ | * | U/S | 31 | B/S | B/S | B/S | U/L | |
- Initial mode is "Upper"
- x/S = Shift to mode x for one character; B/S = shift to 8-bit binary
- x/L = Latch to mode x for following characters
- Punct codes 2–5 encode two bytes each
- The table lists ASCII characters, but it is the byte values that are encoded, even if a non-ASCII character set is in use
B/S (binary shift) is followed by a 5-bit length. If non-zero, this indicates that 1–31 8-bit bytes follow. If zero, 11 additional length bits encode the number of following bytes less 31. (Note that for 32–62 bytes, two 5-bit byte shift sequences are more compact than one 11-bit.) At the end of the binary sequence, the previous mode is resumed.
FLG(n) is followed by a 3-bit n value. n=0 encodes FNC1. n=1–6 is followed by 1–6 digits (in digit mode) which are zero-padded to make a 6-bit ECI identifier. n=7 is reserved and currently illegal.
Mode message
The mode message encodes the number of layers (L layers encoded as the integer L−1), and the number of data codewords (D codewords, encoded as the integer D−1) in the message. All remaining codewords are used as check codewords.
For compact Aztec codes, the number of layers is encoded as a 2-bit value, and the number of data codewords as a 6-bit value, resulting in an 8-bit mode word. For full Aztec codes, the number of layers is encoded in 5 bits, and the number of data codewords is encoded in 11 bits, making a 16-bit mode word.
The mode word is broken into 2 or 4 4-bit codewords in GF(16), and 5 or 6 Reed–Solomon check words are appended, making a 28- or 40-bit mode message, which is wrapped in a 1-pixel layer around the core.
Because an L+1-layer compact Aztec code can hold more data than an L-layer full code, full codes with less than 4 layers are rarely used.
Most importantly, the number of layers determines the size of the Reed–Solomon codewords used. This varies from 6 to 12 bits:
| Bits | Field | Polynomial | Used for |
|---|---|---|---|
| 4 | GF(16) | x4+x+1 | Mode message |
| 6 | GF(64) | x6+x+1 | 1–2 layers |
| 8 | GF(256) | x8+x5+x3+x2+1 | 3–8 layers |
| 10 | GF(1024) | x10+x3+1 | 9–22 layers |
| 12 | GF(4096) | x12+x6+x5+x3+1 | 23–32 layers |
The codeword size b is the smallest even number which ensures that the total number of codewords in the symbol is less than the limit of 2b−1 which can be corrected by a Reed–Solomon code.
As mentioned above, it is recommended that at least 23% of the available codewords, plus 3, are reserved for correction, and a symbol size is chosen such that the message will fit into the available space.
Bit stuffing
The data bits are broken into codewords, with the first bit corresponding to the most significant coefficient. While doing this, code words of all-zero and all-ones are avoided by bit stuffing: if the first b−1 bits of a code word have the same value, an extra bit with the complementary value is inserted into the data stream. This insertion takes place whether or not the last bit of the code word would have had the same value or not.
Also, note that this only applies to strings of b−1 bits at the beginning of a code word. Longer strings of identical bits are permitted as long as they straddle a code word boundary.
When decoding, a code word of all zero or all one may be assumed to be an erasure, and corrected more efficiently than a general error.
This process makes the message longer, and the final number of data codewords recorded in the mode message is not known until it is complete. In rare cases, it may be necessary to jump to the next-largest symbol and begin the process all over again to maintain the minimum fraction of check words.
Padding
After bit stuffing, the data string is padded to the next codeword boundary by appending 1 bit. If this would result in a code word of all ones, the last bit is changed to zero (and will be ignored by the decoder as a bit-stuffing bit). On decoding, the padding bits may be decoded as shift and latch codes, but that will not affect the message content. The reader must accept and ignore a partial code at the end of the message, as long as it is all-ones.
Additionally, if the total number of data bits available in the symbol is not a multiple of the codeword size, the data string is prefixed with an appropriate number of 0 bits to occupy the extra space. These bits are not included in the check word computation.
Check codewords
Both the mode word, and the data, must have check words appended to fill out the available space. This is computed by appending K check words such that the entire message is a multiple of the Reed–Solomon polynomial (x−2)(x−4)...(x−2K).
Note that check words are not subject to bit stuffing, and may be all-zero or all-one. Thus, it is not possible to detect the erasure of a check word.
Laying out the message

A full Aztec code symbol has, in addition to the core, a "reference grid" of alternating black and white pixels occupying every 16th row and column. These known pixels allow a reader to maintain alignment with the pixel grid over large symbols. For up to 4 layers (31×31 pixels), this consists only of single lines extending outward from the core, continuing the alternating pattern. Inside the 5th layer, however, additional rows and columns of alternating pixels are inserted ±16 pixels from the center, so the 5th layer is located ±17 and ±18 pixels from the center, and a 5-layer symbol is 37×37 pixels.
Likewise, additional reference grid rows and columns are inserted ±32 pixels from the center, making a 12-layer symbol 67×67 pixels. In this case, the 12th layer occupies rings ±31 and ±33 pixels from the center. The pattern continues indefinitely outward, with 15-pixel blocks of data separated by rows and columns of the reference grid.
One way to construct the symbol is to delete the reference grid entirely and begin with a 14×14-pixel core centered on a 2×2 pixel-white square. Then break it into 15×15 pixel blocks and insert the reference grid between them.
The mode message begins at the top-left corner of the core and wraps around it clockwise in a 1-bit thick layer. It begins with the most significant bit of the number of layers and ends with the check words. For a compact Aztec code, it is broken into four 7-bit pieces to leave room for the orientation marks. For a full Aztec code, it is broken into four 10-bit pieces, and those pieces are each divided in half by the reference grid.
In some cases, the total capacity of the matrix does not divide evenly by full code words. In such cases, the main message is padded with 0 bits in the beginning. These bits are not included in the check word calculation and should be skipped during decoding. The total matrix capacity for a full symbol can be calculated as (112+16*L)*L for a full Aztec code and (88+16*L)*L for a compact Aztec code, where L is the symbol size in layers.[4] As an example, the total matrix capacity of a compact Aztec code with 1 layer is 104 bits. Since code words are six bits, this gives 17 code words and two extra bits. Two zero bits are prepended to the message as padding and must be skipped during decoding.
The padded main message begins at the outer top-left of the entire symbol and spirals around it counterclockwise in a 2-bit thick layer, ending directly above the top-left corner of the core. This places the bit-stuffed data words, for which erasures can be detected, in the outermost layers of the symbol, which is most prone to erasures. The check words are stored closer to the core. The last check word ends just above the top left corner of the bull's eye.
With the core in its standard orientation, the first bit of the first data word is placed in the upper-left corner, with additional bits placed in a 2-bit-wide column left-to-right and top-to-bottom. This continues until 2 rows from the bottom of the symbol when the pattern rotates 90 degrees counterclockwise and continues in a 2-bit high row, bottom-to-top and left-to-right. After 4 equal-sized quarter layers, the spiral continues with the top-left corner of the next-inner layer, finally ending one pixel above the top-left corner of the core.
Finally, 1 bit are printed as black squares, and 0 bits are printed as white squares.
Usage

Transport
Aztec codes are widely used for transport ticketing.
The Aztec Code has been selected by the airline industry (IATA's BCBP standard) for electronic boarding passes. Several airlines send Aztec Codes to passengers' mobile phones to act as boarding passes. These are often integrated with apps on passengers' phones, including Apple Wallet.
Aztec codes are also used in rail, including by Tehran Metro, British National Rail,[5] Eurostar, Deutsche Bahn, TCDD Taşımacılık, DSB, SJ, České dráhy, Slovak Railways, Slovenian Railways, Croatian Railways, Trenitalia, Nederlandse Spoorwegen, Pasažieru vilciens, PKP Intercity, VR Group, Via Rail, Swiss Federal Railways, SNCB and SNCF for tickets sold online and printed out by customers or displayed on mobile phone screens. The Aztec code is scanned by a handheld scanner by on-train staff or at the turnstile to validate the ticket.
Governmental
Car registration documents in Poland bear a summary, compressed by NRV2E algorithm, encoded as Aztec Code. Works are underway to enable car insurance companies to automatically fill in the relevant information based on digital photographs of the document as the first step of closing a new insurance contract.
Federal Tax Service in Russia encodes payment information in tax notices as Aztec Code.
Commercial
Many bills in Canada are now using this technology as well, including EastLink, Shaw Cable, and Bell Aliant.
See also
References
- ↑
- US 5591956, Longacre, Jr., Andrew & Hussey, Robert, "Two Dimensional Data Encoding Structure and Symbology for use with Optical Readers", published 1997-01-07
- ↑ Official Gazette. United States Patent Office. 17 June 1997.
Hereby dedicates to the public the entire term of said patent.
Click "images" then "correction" to see the dedication to the public domain. - ↑ Adams, Russ. "2-Dimensional Bar Code Page". Archived from the original on 30 April 2010. Retrieved 14 July 2022.
- ↑ "Спецификация Aztec Code (без Small Aztec)" [Aztec Code Specification (without Small Aztec)] (in Russian). Archived from the original on 25 February 2020.
- ↑ "Reversing UK mobile rail tickets". eta.st. 31 January 2023. Retrieved 5 February 2023.
External links
| Linear barcodes | ||
|---|---|---|
| Post office barcodes | ||
| 2D barcodes (stacked) | ||
| 2D barcodes (matrix) | ||
| Polar coordinate barcodes | ||
| Other | ||
| Technological issues | ||
| Other data tags | ||
| Related topics | ||
| ||

