In probability theory, an -divergence is a certain type of function that measures the difference between two probability distributions and . Many common divergences, such as KL-divergence, Hellinger distance, and total variation distance, are special cases of -divergence.




History
These divergences were introduced by Alfréd Rényi[1] in the same paper where he introduced the well-known Rényi entropy. He proved that these divergences decrease in Markov processes. f-divergences were studied further independently by Csiszár (1963), Morimoto (1963) and Ali & Silvey (1966) and are sometimes known as Csiszár -divergences, Csiszár–Morimoto divergences, or Ali–Silvey distances.
Definition
Non-singular case
Let and be two probability distributions over a space , such that , that is, is absolutely continuous with respect to . Then, for a convex function such that is finite for all , , and (which could be infinite), the -divergence of from is defined as


![{\displaystyle f:[0,+\infty )\to (-\infty ,+\infty ]}](../I/6bd0e4f03f33a75809d731c11284772e772f7793.svg)





We call the generator of .

In concrete applications, there is usually a reference distribution on (for example, when , the reference distribution is the Lebesgue measure), such that , then we can use Radon–Nikodym theorem to take their probability densities and , giving






When there is no such reference distribution ready at hand, we can simply define , and proceed as above. This is a useful technique in more abstract proofs.

Extension to singular measures
The above definition can be extended to cases where is no longer satisfied (Definition 7.1 of [2]).
Since is convex, and , the function must nondecrease, so there exists , taking value in .


![{\displaystyle (-\infty ,+\infty ]}](../I/10bc6328d36141218e5998ad6f06567ad93e458a.svg)
Since for any , we have , we can extend f-divergence to the .



Properties
Basic relations between f-divergences
- Linearity: given a finite sequence of nonnegative real numbers and generators .



- iff for some .



If , then by definition.
Conversely, if , then let . For any two probability measures on the set , since , we get






Since each probability measure has one degree of freedom, we can solve for every choice of .


Linear algebra yields , which is a valid probability measure. Then we obtain .


Thus for some constants . Plugging the formula into yields .




Basic properties of f-divergences
- Non-negativity: the ƒ-divergence is always positive; it is zero if the measures P and Q coincide. This follows immediately from Jensen’s inequality:
- Data-processing inequality: if κ is an arbitrary transition probability that transforms measures P and Q into Pκ and Qκ correspondingly, then
- Joint convexity: for any 0 ≤ λ ≤ 1,
- Reversal by convex inversion: for any function , its convex inversion is defined as . When satisfies the defining features of a f-divergence generator ( is finite for all , , and ), then satisfies the same features, and thus defines a f-divergence . This is the "reverse" of , in the sense that for all that are absolutely continuous with respect to each other. In this way, every f-divergence can be turned symmetric by . For example, performing this symmetrization turns KL-divergence into Jensen-Shannon divergence.










In particular, the monotonicity implies that if a Markov process has a positive equilibrium probability distribution then is a monotonic (non-increasing) function of time, where the probability distribution is a solution of the Kolmogorov forward equations (or Master equation), used to describe the time evolution of the probability distribution in the Markov process. This means that all f-divergences are the Lyapunov functions of the Kolmogorov forward equations. The converse statement is also true: If is a Lyapunov function for all Markov chains with positive equilibrium and is of the trace-form () then , for some convex function f.[3][4] For example, Bregman divergences in general do not have such property and can increase in Markov processes.[5]






Analytic properties
The f-divergences can be expressed using Taylor series and rewritten using a weighted sum of chi-type distances (Nielsen & Nock (2013)).
Naive variational representation
Let be the convex conjugate of . Let be the effective domain of , that is, . Then we have two variational representations of , which we describe below.



Basic variational representation
Under the above setup,
Theorem — .
![{\displaystyle D_{f}(P;Q)=\sup _{g:\Omega \to \mathrm {effdom} (f^{*})}E_{P}[g]-E_{Q}[f^{*}\circ g]}](../I/bfeaea75682a9e7d25e958c5140f04bb38ee8e33.svg)
This is Theorem 7.24 in.[2]
Example applications
Using this theorem on total variation distance, with generator its convex conjugate is , and we obtain

![{\displaystyle f^{*}(x^{*})={\begin{cases}x^{*}{\text{ on }}[-1/2,1/2],\\+\infty {\text{ else.}}\end{cases}}}](../I/9e7c003b1039ee6b1ae107c19a4b63368768297e.svg)
![{\displaystyle TV(P\|Q)=\sup _{|g|\leq 1/2}E_{P}[g(X)]-E_{Q}[g(X)].}](../I/ac58a93075bb971e1ff82d2da86052bc44953e39.svg)
For chi-squared divergence, defined by , we obtain

![{\displaystyle \chi ^{2}(P;Q)=\sup _{g}E_{P}[g(X)]-E_{Q}[g(X)^{2}/4+g(X)].}](../I/fad615f1e943d1d8f35166bf75411bcdc6a34d44.svg)
Since the variation term is not affine-invariant in , even though the domain over which varies is affine-invariant, we can use up the affine-invariance to obtain a leaner expression.
Replacing by and taking the maximum over , we obtain


![{\displaystyle \chi ^{2}(P;Q)=\sup _{g}{\frac {(E_{P}[g(X)]-E_{Q}[g(X)])^{2}}{Var_{Q}[g(X)]}},}](../I/30f0341eeefd0f5ae785c7afab21e034efac27a3.svg)
which is just a few steps away from the Hammersley–Chapman–Robbins bound and the Cramér–Rao bound (Theorem 29.1 and its corollary in [2]).
For -divergence with , we have , with range . Its convex conjugate is with range , where .







Applying this theorem yields, after substitution with ,

![{\displaystyle D_{\alpha }(P\|Q)={\frac {1}{\alpha (1-\alpha )}}-\inf _{h:\Omega \to (0,\infty )}\left(E_{Q}\left[{\frac {h^{\alpha }}{\alpha }}\right]+E_{P}\left[{\frac {h^{\alpha -1}}{1-\alpha }}\right]\right),}](../I/743408da5cc53267450ad31f5bb533be12416c03.svg)
or, releasing the constraint on ,

![{\displaystyle D_{\alpha }(P\|Q)={\frac {1}{\alpha (1-\alpha )}}-\inf _{h:\Omega \to \mathbb {R} }\left(E_{Q}\left[{\frac {|h|^{\alpha }}{\alpha }}\right]+E_{P}\left[{\frac {|h|^{\alpha -1}}{1-\alpha }}\right]\right).}](../I/9f7da683e910fa65e72b6c72663fc74f9e3ab20d.svg)
Setting yields the variational representation of -divergence obtained above.


The domain over which varies is not affine-invariant in general, unlike the -divergence case. The -divergence is special, since in that case, we can remove the from .


For general , the domain over which varies is merely scale invariant. Similar to above, we can replace by , and take minimum over to obtain


![{\displaystyle D_{\alpha }(P\|Q)=\sup _{h>0}\left[{\frac {1}{\alpha (1-\alpha )}}\left(1-{\frac {E_{P}[h^{\alpha -1}]^{\alpha }}{E_{Q}[h^{\alpha }]^{\alpha -1}}}\right)\right].}](../I/7072491ecc94ba97d0927d3f3a1212b3b5410faa.svg)
Setting , and performing another substitution by , yields two variational representations of the squared Hellinger distance:


![{\displaystyle H^{2}(P\|Q)={\frac {1}{2}}D_{1/2}(P\|Q)=2-\inf _{h>0}\left(E_{Q}\left[h(X)\right]+E_{P}\left[h(X)^{-1}\right]\right),}](../I/12e5e27f2c2eb343339c4d783b6e0b0c90140977.svg)
![{\displaystyle H^{2}(P\|Q)=2\sup _{h>0}\left(1-{\sqrt {E_{P}[h^{-1}]E_{Q}[h]}}\right).}](../I/c99bfe5824420b43a41d87085e1327a0d560ded1.svg)
Applying this theorem to the KL-divergence, defined by , yields

![{\displaystyle D_{KL}(P;Q)=\sup _{g}E_{P}[g(X)]-e^{-1}E_{Q}[e^{g(X)}].}](../I/c7bf2e43b66e0cbfef68f43c5602f030325afd53.svg)
This is strictly less efficient than the Donsker–Varadhan representation
![{\displaystyle D_{KL}(P;Q)=\sup _{g}E_{P}[g(X)]-\ln E_{Q}[e^{g(X)}].}](../I/c5eea8b27a9c6eb703f5f7e426a7f3c07e973342.svg)
This defect is fixed by the next theorem.
Improved variational representation
Assume the setup in the beginning of this section ("Variational representations").
Theorem — If on (redefine if necessary), then


,
![{\displaystyle D_{f}(P\|Q)=f^{\prime }(\infty )P\left[S^{c}\right]+\sup _{g}\mathbb {E} _{P}\left[g1_{S}\right]-\Psi _{Q,P}^{*}(g)}](../I/e7c2ce87a5d7b1481296363089097899034e62fa.svg)
where and , where is the probability density function of with respect to some underlying measure.
![{\displaystyle \Psi _{Q,P}^{*}(g):=\inf _{a\in \mathbb {R} }\mathbb {E} _{Q}\left[f^{*}(g(X)-a)\right]+aP[S]}](../I/57ac44a7ebd83d1b8130b3a595b31785a841808b.svg)

In the special case of , we have

.
![{\displaystyle D_{f}(P\|Q)=\sup _{g}\mathbb {E} _{P}[g]-\Psi _{Q}^{*}(g),\quad \Psi _{Q}^{*}(g):=\inf _{a\in \mathbb {R} }\mathbb {E} _{Q}\left[f^{*}(g(X)-a)\right]+a}](../I/48ee17a4b6e07baf70b42bf1c040a3fed50b7f04.svg)
This is Theorem 7.25 in.[2]
Example applications
Applying this theorem to KL-divergence yields the Donsker–Varadhan representation.
Attempting to apply this theorem to the general -divergence with does not yield a closed-form solution.
Common examples of f-divergences
The following table lists many of the common divergences between probability distributions and the possible generating functions to which they correspond. Notably, except for total variation distance, all others are special cases of -divergence, or linear sums of -divergences.
For each f-divergence , its generating function is not uniquely defined, but only up to , where is any real constant. That is, for any that generates an f-divergence, we have . This freedom is not only convenient, but actually necessary.



| Divergence | Corresponding f(t) |
|---|---|
| -divergence, | |
| Total variation distance () | |
| α-divergence | |
| KL-divergence () | |
| reverse KL-divergence () | |
| Jensen–Shannon divergence | |
| Jeffrey's divergence (KL + reverse KL) | |
| squared Hellinger distance () | |
| Pearson -divergence (rescaling of ) | |
| Neyman -divergence (reverse Pearson)
(rescaling of ) |
















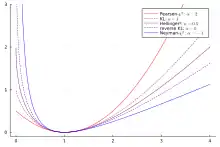
Let be the generator of -divergence, then and are convex inversions of each other, so . In particular, this shows that the squared Hellinger distance and Jensen-Shannon divergence are symmetric.



In the literature, the -divergences are sometimes parametrized as

which is equivalent to the parametrization in this page by substituting .

Relations to other statistical divergences
Here, we compare f-divergences with other statistical divergences.
Rényi divergence
The Rényi divergences is a family of divergences defined by
![{\displaystyle R_{\alpha }(P\|Q)={\frac {1}{\alpha -1}}\log {\Bigg (}E_{Q}\left[\left({\frac {dP}{dQ}}\right)^{\alpha }\right]{\Bigg )}\,}](../I/7b29d7782046392b0f57dea2d183bc4549c231d4.svg)
when . It is extended to the cases of by taking the limit.


Simple algebra shows that , where is the -divergence defined above.


Bregman divergence
The only f-divergence that is also a Bregman divergence is the KL divergence.[6]
Integral probability metrics
The only f-divergence that is also an integral probability metric is the total variation.[7]
Financial interpretation
A pair of probability distributions can be viewed as a game of chance in which one of the distributions defines the official odds and the other contains the actual probabilities. Knowledge of the actual probabilities allows a player to profit from the game. For a large class of rational players the expected profit rate has the same general form as the ƒ-divergence.[8]
See also
References
- ↑ Rényi, Alfréd (1961). On measures of entropy and information (PDF). The 4th Berkeley Symposium on Mathematics, Statistics and Probability, 1960. Berkeley, CA: University of California Press. pp. 547–561. Eq. (4.20)
- 1 2 3 4 Polyanskiy, Yury; Yihong, Wu (2022). Information Theory: From Coding to Learning (draft of October 20, 2022) (PDF). Cambridge University Press. Archived from the original (PDF) on 2023-02-01.
- ↑ Gorban, Pavel A. (15 October 2003). "Monotonically equivalent entropies and solution of additivity equation". Physica A. 328 (3–4): 380–390. arXiv:cond-mat/0304131. Bibcode:2003PhyA..328..380G. doi:10.1016/S0378-4371(03)00578-8. S2CID 14975501.
- ↑ Amari, Shun'ichi (2009). Leung, C.S.; Lee, M.; Chan, J.H. (eds.). Divergence, Optimization, Geometry. The 16th International Conference on Neural Information Processing (ICONIP 20009), Bangkok, Thailand, 1--5 December 2009. Lecture Notes in Computer Science, vol 5863. Berlin, Heidelberg: Springer. pp. 185–193. doi:10.1007/978-3-642-10677-4_21.
- ↑ Gorban, Alexander N. (29 April 2014). "General H-theorem and Entropies that Violate the Second Law". Entropy. 16 (5): 2408–2432. arXiv:1212.6767. Bibcode:2014Entrp..16.2408G. doi:10.3390/e16052408.
- ↑ Jiao, Jiantao; Courtade, Thomas; No, Albert; Venkat, Kartik; Weissman, Tsachy (December 2014). "Information Measures: the Curious Case of the Binary Alphabet". IEEE Transactions on Information Theory. 60 (12): 7616–7626. arXiv:1404.6810. doi:10.1109/TIT.2014.2360184. ISSN 0018-9448. S2CID 13108908.
- ↑ Sriperumbudur, Bharath K.; Fukumizu, Kenji; Gretton, Arthur; Schölkopf, Bernhard; Lanckriet, Gert R. G. (2009). "On integral probability metrics, φ-divergences and binary classification". arXiv:0901.2698 [cs.IT].
- ↑ Soklakov, Andrei N. (2020). "Economics of Disagreement—Financial Intuition for the Rényi Divergence". Entropy. 22 (8): 860. arXiv:1811.08308. Bibcode:2020Entrp..22..860S. doi:10.3390/e22080860. PMC 7517462. PMID 33286632.
- Csiszár, I. (1963). "Eine informationstheoretische Ungleichung und ihre Anwendung auf den Beweis der Ergodizitat von Markoffschen Ketten". Magyar. Tud. Akad. Mat. Kutato Int. Kozl. 8: 85–108.
- Morimoto, T. (1963). "Markov processes and the H-theorem". J. Phys. Soc. Jpn. 18 (3): 328–331. Bibcode:1963JPSJ...18..328M. doi:10.1143/JPSJ.18.328.
- Ali, S. M.; Silvey, S. D. (1966). "A general class of coefficients of divergence of one distribution from another". Journal of the Royal Statistical Society, Series B. 28 (1): 131–142. JSTOR 2984279. MR 0196777.
- Csiszár, I. (1967). "Information-type measures of difference of probability distributions and indirect observation". Studia Scientiarum Mathematicarum Hungarica. 2: 229–318.
- Csiszár, I.; Shields, P. (2004). "Information Theory and Statistics: A Tutorial" (PDF). Foundations and Trends in Communications and Information Theory. 1 (4): 417–528. doi:10.1561/0100000004. Retrieved 2009-04-08.
- Liese, F.; Vajda, I. (2006). "On divergences and informations in statistics and information theory". IEEE Transactions on Information Theory. 52 (10): 4394–4412. doi:10.1109/TIT.2006.881731. S2CID 2720215.
- Nielsen, F.; Nock, R. (2013). "On the Chi square and higher-order Chi distances for approximating f-divergences". IEEE Signal Processing Letters. 21 (1): 10–13. arXiv:1309.3029. Bibcode:2014ISPL...21...10N. doi:10.1109/LSP.2013.2288355. S2CID 4152365.
- Coeurjolly, J-F.; Drouilhet, R. (2006). "Normalized information-based divergences". arXiv:math/0604246.