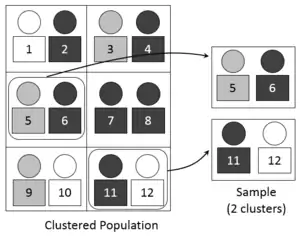
In statistics, cluster sampling is a sampling plan used when mutually homogeneous yet internally heterogeneous groupings are evident in a statistical population. It is often used in marketing research.
In this sampling plan, the total population is divided into these groups (known as clusters) and a simple random sample of the groups is selected. The elements in each cluster are then sampled. If all elements in each sampled cluster are sampled, then this is referred to as a "one-stage" cluster sampling plan. If a simple random subsample of elements is selected within each of these groups, this is referred to as a "two-stage" cluster sampling plan. A common motivation for cluster sampling is to reduce the total number of interviews and costs given the desired accuracy. For a fixed sample size, the expected random error is smaller when most of the variation in the population is present internally within the groups, and not between the groups.
Cluster elemental
The population within a cluster should ideally be as heterogeneous as possible, but there should be homogeneity between clusters. Each cluster should be a small-scale representation of the total population. The clusters should be mutually exclusive and collectively exhaustive. A random sampling technique is then used on any relevant clusters to choose which clusters to include in the study. In single-stage cluster sampling, all the elements from each of the selected clusters are sampled. In two-stage cluster sampling, a random sampling technique is applied to the elements from each of the selected clusters.
The main difference between cluster sampling and stratified sampling is that in cluster sampling the cluster is treated as the sampling unit so sampling is done on a population of clusters (at least in the first stage). In stratified sampling, the sampling is done on elements within each stratum. In stratified sampling, a random sample is drawn from each of the strata, whereas in cluster sampling only the selected clusters are sampled. A common motivation for cluster sampling is to reduce costs by increasing sampling efficiency. This contrasts with stratified sampling where the motivation is to increase precision.
There is also multistage cluster sampling, where at least two stages are taken in selecting elements from clusters.
When clusters are of different sizes
Without modifying the estimated parameter, cluster sampling is unbiased when the clusters are approximately the same size. In this case, the parameter is computed by combining all the selected clusters. When the clusters are of different sizes there are several options:
One method is to sample clusters and then survey all elements in that cluster. Another method is a two-stage method of sampling a fixed proportion of units (be it 5% or 50%, or another number, depending on cost considerations) from within each of the selected clusters. Relying on the sample drawn from these options will yield an unbiased estimator. However, the sample size is no longer fixed upfront. This leads to a more complicated formula for the standard error of the estimator, as well as issues with the optics of the study plan (since the power analysis and the cost estimations often relate to a specific sample size).
A third possible solution is to use probability proportionate to size sampling. In this sampling plan, the probability of selecting a cluster is proportional to its size, so a large cluster has a greater probability of selection than a small cluster. The advantage here is that when clusters are selected with probability proportionate to size, the same number of interviews should be carried out in each sampled cluster so that each unit sampled has the same probability of selection.
Applications of cluster sampling
An example of cluster sampling is area sampling or geographical cluster sampling. Each cluster is a geographical area in an area sampling frame. Because a geographically dispersed population can be expensive to survey, greater economy than simple random sampling can be achieved by grouping several respondents within a local area into a cluster. It is usually necessary to increase the total sample size to achieve equivalent precision in the estimators, but cost savings may make such an increase in sample size feasible.
For the organization of a population census, the first step is usually dividing the overall geographic area into enumeration areas or census tracts for the field work organization. Enumeration areas may be also useful as first-stage units for cluster sampling in many types of surveys. When a population census is outdated, the list of individuals should not be directly used as sampling frame for a socio-economic survey. Updating the whole census is economically unfeasable. A good alternative may be keeping the old enumeration areas, with some update in higly dynamic areas, such as urban suburbs, selecting a sample of enumeration areas and updating the list of individuals or households only in the selected enumeration areas.[1]
Cluster sampling is used to estimate low mortalities in cases such as wars, famines and natural disasters.[2]
Fisheries science
It is almost impossible to take a simple random sample of fish from a population, which would require that individuals are captured individually and at random.[3] This is because fishing gears capture fish in groups (or clusters).
In commercial fisheries sampling, the costs of operating at sea are often too large to select hauls individually and at random. Therefore, observations are further clustered by either vessel or fishing trip.
Advantages
- Can be cheaper than other sampling plans – e.g. fewer travel expenses, and administration cost.
- Feasibility: This sampling plan takes large populations into account. Since these groups are so small, deploying any other sampling plan would be very costly.
- Economy: The regular two major concerns of expenditure, i.e., traveling and listing, are greatly reduced in this method. For example: Compiling research information about every household in a city would be very costly, whereas compiling information about various blocks of the city will be more economical. Here, traveling as well as listing efforts will be greatly reduced.
- Reduced variability: in the rare case of a negative intraclass correlation between subjects within a cluster, the estimators produced by cluster sampling will yield more accurate estimates than data obtained from a simple random sample (i.e. the design effect will be larger than 1). This is not a commonplace scenario.
Major use: when the sampling frame of all elements is not available we can resort only to cluster sampling.
Disadvantages
- Higher sampling error, which can be expressed by the design effect: the ratio between the variance of an estimator made from the samples of the cluster study and the variance of an estimator obtained from a sample of subjects in an equally reliable, randomly sampled unclustered study.[4] The larger the intraclass correlation is between subjects within a cluster the worse the design effect becomes (i.e. the larger it gets from 1. Indicating a larger expected increase in the variance of the estimator). In other words, the more there is heterogeneity between clusters and more homogeneity between subjects within a cluster, the less accurate our estimators become. This is because in such cases we are better on sampling as many clusters as we can and making do with a small sample of subjects from within each cluster (i.e. two-stage cluster sampling).
- Complexity. Cluster sampling is more sophisticated and requires more attention with how to plan and how to analyze (i.e.: to take into account the weights of subjects during the estimation of parameters, confidence intervals, etc.)
More on cluster sampling
Two-stage cluster sampling
Two-stage cluster sampling, a simple case of multistage sampling, is obtained by selecting cluster samples in the first stage and then selecting a sample of elements from every sampled cluster. Consider a population of N clusters in total. In the first stage, n clusters are selected using the ordinary cluster sampling method. In the second stage, simple random sampling is usually used.[5] It is used separately in every cluster and the numbers of elements selected from different clusters are not necessarily equal. The total number of clusters N, the number of clusters selected n, and the numbers of elements from selected clusters need to be pre-determined by the survey designer. Two-stage cluster sampling aims at minimizing survey costs and at the same time controlling the uncertainty related to estimates of interest.[6] This method can be used in health and social sciences. For instance, researchers used two-stage cluster sampling to generate a representative sample of the Iraqi population to conduct mortality surveys.[7] Sampling in this method can be quicker and more reliable than other methods, which is why this method is now used frequently.
Inference when the number of clusters is small
Cluster sampling methods can lead to significant bias when working with a small number of clusters. For instance, it can be necessary to cluster at the state or city-level, units that may be small and fixed in number. Microeconometrics methods for panel data often use short panels, which is analogous to having few observations per clusters and many clusters. The small cluster problem can be viewed as an incidental parameter problem.[8] While the point estimates can be reasonably precisely estimated, if the number of observations per cluster is sufficiently high, we need the number of clusters for the asymptotics to kick in. If the number of clusters is low the estimated covariance matrix can be downward biased.[9]

Small numbers of clusters are a risk when there is serial correlation or when there is intraclass correlation as in the Moulton context. When having few clusters, we tend to underestimate serial correlation across observations when a random shock occurs, or the intraclass correlation in a Moulton setting.[10] Several studies have highlighted the consequences of serial correlation and highlighted the small-cluster problem.[11][12]
In the framework of the Moulton factor, an intuitive explanation of the small cluster problem can be derived from the formula for the Moulton factor. Assume for simplicity that the number of observations per cluster is fixed at n. Below, stands for the covariance matrix adjusted for clustering, stands for the covariance matrix not adjusted for clustering, and ρ stands for the intraclass correlation:



The ratio on the left-hand side indicates how much the unadjusted scenario overestimates the precision. Therefore, a high number means a strong downward bias of the estimated covariance matrix. A small cluster problem can be interpreted as a large n: when the data is fixed and the number of clusters is low, the number of data within a cluster can be high. It follows that inference, when the number of clusters is small, will not have the correct coverage.[10]
Several solutions for the small cluster problem have been proposed. One can use a bias-corrected cluster-robust variance matrix, make T-distribution adjustments, or use bootstrap methods with asymptotic refinements, such as the percentile-t or wild bootstrap, that can lead to improved finite sample inference.[9] Cameron, Gelbach and Miller (2008) provide microsimulations for different methods and find that the wild bootstrap performs well in the face of a small number of clusters.[13]
See also
References
- ↑ "HANDBOOK ON Master Sampling Frames for Agricultural Statistics - PDF Free Download". docplayer.net. Retrieved 2024-01-10.
- ↑ David Brown, Study Claims Iraq's 'Excess' Death Toll Has Reached 655,000, Washington Post, Wednesday, October 11, 2006. Retrieved September 14, 2010.
- ↑ Nelson, Gary A. (July 2014). "Cluster Sampling: A Pervasive, Yet Little Recognized Survey Design in Fisheries Research". Transactions of the American Fisheries Society. 143 (4): 926–938. Bibcode:2014TrAFS.143..926N. doi:10.1080/00028487.2014.901252.
- ↑ Kerry and Bland (1998). Statistics notes: The intracluster correlation coefficient in cluster randomization. British Medical Journal, 316, 1455–1460.
- ↑ Ahmed, Saifuddin (2009). Methods in Sample Surveys (PDF). The Johns Hopkins University and Saifuddin Ahmed. Archived (PDF) from the original on 2013-09-28.
- ↑ Daniel Pfeffermann; C. Radhakrishna Rao (2009). Handbook of Statistics Vol.29A Sample Surveys: Theory, Methods and Infernece. Elsevier B.V. ISBN 978-0-444-53124-7.
- ↑ LP Galway; Nathaniel Bell; Al S SAE; Amy Hagopian; Gilbert Burnham; Abraham Flaxman; Wiliam M Weiss; Julie Rajaratnam; Tim K Takaro (27 April 2012). "A two-stage cluster sampling method using gridded population data, a GIS, and Google EarthTM imagery in a population-based mortality survey in Iraq". International Journal of Health Geographics. 11: 12. doi:10.1186/1476-072X-11-12. PMC 3490933. PMID 22540266.
- ↑ Cameron A. C. and P. K. Trivedi (2005): Microeconometrics: Methods and Applications. Cambridge University Press, New York.
- 1 2 Cameron, C. and D. L. Miller (2015): A Practitioner's Guide to Cluster-Robust Inference. Journal of Human Resources 50(2), pp. 317–372.
- 1 2 Angrist, J.D. and J.-S. Pischke (2009): Mostly Harmless Econometrics. An empiricist's companion. Princeton University Press, New Jersey.
- ↑ Bertrand, M., E. Duflo and S. Mullainathan (2004): How Much Should We Trust Differences-in-Differences Estimates? Quarterly Journal of Economics 119(1), pp. 249–275.
- ↑ Kezdi, G. (2004): Robust Standard Error Estimation in Fixed-Effect Panel Models. Hungarian Statistical Review 9, pp. 95–116.
- ↑ Cameron, C., J. Gelbach and D. L. Miller (2008): Bootstrap-Based Improvements for Inference with Clustered Errors. The Review of Economics and Statistics 90, pp. 414–427.