A Gap penalty is a method of scoring alignments of two or more sequences. When aligning sequences, introducing gaps in the sequences can allow an alignment algorithm to match more terms than a gap-less alignment can. However, minimizing gaps in an alignment is important to create a useful alignment. Too many gaps can cause an alignment to become meaningless. Gap penalties are used to adjust alignment scores based on the number and length of gaps. The five main types of gap penalties are constant, linear, affine, convex, and profile-based.[1]
Applications
- Genetic sequence alignment - In bioinformatics, gaps are used to account for genetic mutations occurring from insertions or deletions in the sequence, sometimes referred to as indels. Insertions or deletions can occur due to single mutations, unbalanced crossover in meiosis, slipped strand mispairing, and chromosomal translocation.[2] The notion of a gap in an alignment is important in many biological applications, since the insertions or deletions comprise an entire sub-sequence and often occur from a single mutational event.[3] Furthermore, single mutational events can create gaps of different sizes. Therefore, when scoring, the gaps need to be scored as a whole when aligning two sequences of DNA. Considering multiple gaps in a sequence as a larger single gap will reduce the assignment of a high cost to the mutations. For instance, two protein sequences may be relatively similar but differ at certain intervals as one protein may have a different subunit compared to the other. Representing these differing sub-sequences as gaps will allow us to treat these cases as “good matches” even though there are long consecutive runs with indel operations in the sequence. Therefore, using a good gap penalty model will avoid low scores in alignments and improve the chances of finding a true alignment.[3] In genetic sequence alignments, gaps are represented as dashes(-) on a protein/DNA sequence alignment.[1]
- Unix diff function - computes the minimal difference between two files similarly to plagiarism detection.
- Spell checking - Gap penalties can help find correctly spelled words with the shortest edit distance to a misspelled word. Gaps can indicate a missing letter in the incorrectly spelled word.
- Plagiarism detection - Gap penalties allow algorithms to detect where sections of a document are plagiarized by placing gaps in original sections and matching what is identical. The gap penalty for a certain document quantifies how much of a given document is probably original or plagiarized.
Bioinformatics applications
Global alignment
A global alignment performs an end-to-end alignment of the query sequence with the reference sequence. Ideally, this alignment technique is most suitable for closely related sequences of similar lengths. The Needleman-Wunsch algorithm is a dynamic programming technique used to conduct global alignment. Essentially, the algorithm divides the problem into a set of sub-problems, then uses the results of the sub-problems to reconstruct a solution to the original query.[4]
Semi-global alignment
The use of semi-global alignment exists to find a particular match within a large sequence. An example includes seeking promoters within a DNA sequence. Unlike global alignment, it compromises of no end gaps in one or both sequences. If the end gaps are penalized in one sequence 1 but not in sequence 2, it produces an alignment that contains sequence 2 within sequence 1.
Local alignment

A local sequence alignment matches a contiguous sub-section of one sequence with a contiguous sub-section of another.[5] The Smith-Waterman algorithm is motivated by giving scores for matches and mismatches. Matches increase the overall score of an alignment whereas mismatches decrease the score. A good alignment then has a positive score and a poor alignment has a negative score. The local algorithm finds an alignment with the highest score by considering only alignments that score positives and picking the best one from those. The algorithm is a dynamic programming algorithm. When comparing proteins, one uses a similarity matrix which assigns a score to each possible residue pair. The score should be positive for similar residues and negative for dissimilar residue pairs. Gaps are usually penalized using a linear gap function that assigns an initial penalty for a gap opening, and an additional penalty for gap extensions, increasing the gap length.
Scoring matrix

Substitution matrices such as BLOSUM are used for sequence alignment of proteins.[6] A Substitution matrix assigns a score for aligning any possible pair of residues.[6] In general, different substitution matrices are tailored to detecting similarities among sequences that are diverged by differing degrees. A single matrix may be reasonably efficient over a relatively broad range of evolutionary change.[6] The BLOSUM-62 matrix is one of the best substitution matrices for detecting weak protein similarities.[6] BLOSUM matrices with high numbers are designed for comparing closely related sequences, while those with low numbers are designed for comparing distant related sequences. For example, BLOSUM-80 is used for alignments that are more similar in sequence, and BLOSUM-45 is used for alignments that have diverged from each other.[6] For particularly long and weak alignments, the BLOSUM-45 matrix may provide the best results. Short alignments are more easily detected using a matrix with a higher "relative entropy" than that of BLOSUM-62. The BLOSUM series does not include any matrices with relative entropies suitable for the shortest queries.[6]
Indels
During DNA replication, the cellular replication machinery is prone to making two types of errors while duplicating the DNA. These two replication errors are insertions and deletions of single DNA bases from the DNA strand (indels).[7] Indels can have severe biological consequences by causing mutations in the DNA strand that could result in the inactivation or over activation of the target protein. For example, if a one or two nucleotide indel occurs in a coding sequence the result will be a shift in the reading frame, or a frameshift mutation that may render the protein inactive.[7] The biological consequences of indels are often deleterious and are frequently associated with pathologies such as cancer. However, not all indels are frameshift mutations. If indels occur in trinucleotides, the result is an extension of the protein sequence that may also have implications on protein function.[7]
Types
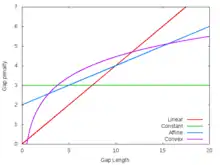
Constant
This is the simplest type of gap penalty: a fixed negative score is given to every gap, regardless of its length.[3][8] This encourages the algorithm to make fewer, larger, gaps leaving larger contiguous sections.
ATTGACCTGA || ||||| AT---CCTGA
Aligning two short DNA sequences, with '-' depicting a gap of one base pair. If each match was worth 1 point and the whole gap -1, the total score: 7 − 1 = 6.
Linear
Compared to the constant gap penalty, the linear gap penalty takes into account the length (L) of each insertion/deletion in the gap. Therefore, if the penalty for each inserted/deleted element is B and the length of the gap L; the total gap penalty would be the product of the two BL.[9] This method favors shorter gaps, with total score decreasing with each additional gap.
ATTGACCTGA || ||||| AT---CCTGA
Unlike constant gap penalty, the size of the gap is considered. With a match with score 1 and each gap -1, the score here is (7 − 3 = 4).
Affine
The most widely used gap penalty function is the affine gap penalty. The affine gap penalty combines the components in both the constant and linear gap penalty, taking the form . This introduces new terms, A is known as the gap opening penalty, B the gap extension penalty and L the length of the gap. Gap opening refers to the cost required to open a gap of any length, and gap extension the cost to extend the length of an existing gap by 1.[10] Often it is unclear as to what the values A and B should be as it differs according to purpose. In general, if the interest is to find closely related matches (e.g. removal of vector sequence during genome sequencing), a higher gap penalty should be used to reduce gap openings. On the other hand, gap penalty should be lowered when interested in finding a more distant match.[9] The relationship between A and B also have an effect on gap size. If the size of the gap is important, a small A and large B (more costly to extend a gap) is used and vice versa. Only the ratio A/B is important, as multiplying both by the same positive constant will increase all penalties by : which does not change the relative penalty between different alignments.



Convex
Using the affine gap penalty requires the assigning of fixed penalty values for both opening and extending a gap. This can be too rigid for use in a biological context.[11]
The logarithmic gap takes the form and was proposed as studies had shown the distribution of indel sizes obey a power law.[12] Another proposed issue with the use of affine gaps is the favoritism of aligning sequences with shorter gaps. Logarithmic gap penalty was invented to modify the affine gap so that long gaps are desirable.[11] However, in contrast to this, it has been found that using logarithmatic models had produced poor alignments when compared to affine models.[12]

Profile-based
Profile–profile alignment algorithms are powerful tools for detecting protein homology relationships with improved alignment accuracy.[13] Profile-profile alignments are based on the statistical indel frequency profiles from multiple sequence alignments generated by PSI-BLAST searches.[13] Rather than using substitution matrices to measure the similarity of amino acid pairs, profile–profile alignment methods require a profile-based scoring function to measure the similarity of profile vector pairs.[13] Profile-profile alignments employ gap penalty functions. The gap information is usually used in the form of indel frequency profiles, which is more specific for the sequences to be aligned. ClustalW and MAFFT adopted this kind of gap penalty determination for their multiple sequence alignments.[13] Alignment accuracies can be improved using this model, especially for proteins with low sequence identity. Some profile–profile alignment algorithms also run the secondary structure information as one term in their scoring functions, which improves alignment accuracy.[13]
Comparing time complexities
The use of alignment in computational biology often involves sequences of varying lengths. It is important to pick a model that would efficiently run at a known input size. The time taken to run the algorithm is known as the time complexity.
| Type | Time |
|---|---|
| Constant gap penalty | O(mn) |
| Affine gap penalty | O(mn) |
| Convex gap penalty | O(mn lg(m+n)) |
Challenges
There are a few challenges when it comes to working with gaps. When working with popular algorithms there seems to be little theoretical basis for the form of the gap penalty functions.[14] Consequently, for any alignment situation gap placement must be empirically determined.[14] Also, pairwise alignment gap penalties, such as the affine gap penalty, are often implemented independent of the amino acid types in the inserted or deleted fragment or at the broken ends, despite evidence that specific residue types are preferred in gap regions.[14] Finally, alignment of sequences implies alignment of the corresponding structures, but the relationships between structural features of gaps in proteins and their corresponding sequences are only imperfectly known. Because of this incorporating structural information into gap penalties is difficult to do.[14] Some algorithms use predicted or actual structural information to bias the placement of gaps. However, only a minority of sequences have known structures, and most alignment problems involve sequences of unknown secondary and tertiary structure.[14]
References
- 1 2 "Glossary". Rosalind. Rosalind Team. Retrieved 2021-05-20.
- ↑ Carroll, Ridge, Clement, Snell, Hyrum , Perry, Mark, Quinn (January 1, 2007). "Effects of Gap Open and Gap Extension Penalties" (PDF). International Journal of Bioinformatics Research and Applications. Retrieved 2014-09-09.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - 1 2 3 "Gap Penalty" (PDF). Algorithms for Molecular Biology. 2006-01-01. Archived from the original (PDF) on 2013-06-26. Retrieved 2014-09-13.
- ↑ Lesk, Arthur M (2013-07-26). "bioinformatics". Encyclopædia Britannica. Retrieved 2014-09-12.
- ↑ Vingron, M.; Waterman, M. S. (1994). "Sequence alignment and penalty choice. Review of concepts, case studies and implications". Journal of Molecular Biology. 235 (1): 1–12. doi:10.1016/S0022-2836(05)80006-3. PMID 8289235.
- 1 2 3 4 5 6 "BLAST substitution matrices". NCBI. Retrieved 2012-11-27.
- 1 2 3 Garcia-Diaz, Miguel (2006). "Mechanism of a genetic glissando: structural biology of indel mutations". Trends in Biochemical Sciences. 31 (4): 206–214. doi:10.1016/j.tibs.2006.02.004. PMID 16545956.
- ↑ "Glossary - Constant Gap Penalty". Rosalind. Rosalind Team. 12 Aug 2014. Retrieved 12 Aug 2014.
- 1 2 Hodgman C, French A, Westhead D (2009). BIOS Instant Notes in Bioinformatics. Garland Science. pp. 143–144. ISBN 978-0203967249.
- ↑ "Global Alignment with Scoring Matrix and Affine Gap Penalty". Rosalind. Rosalind Team. 2012-07-02. Retrieved 2014-09-12.
- 1 2 Sung, Wing-Kin (2011). Algorithms in Bioinformatics : A Practical Introduction. CRC Press. pp. 42–47. ISBN 978-1420070347.
- 1 2 Cartwright, Reed (2006-12-05). "Logarithmic gap costs decrease alignment accuracy". BMC Bioinformatics. 7: 527. doi:10.1186/1471-2105-7-527. PMC 1770940. PMID 17147805.
- 1 2 3 4 5 Wang C, Yan RX, Wang XF, Si JN, Zhang Z (12 October 2011). "Comparison of linear gap penalties and profile-based variable gap penalties in profile-profile alignments". Comput Biol Chem. 35 (5): 308–318. doi:10.1016/j.compbiolchem.2011.07.006. PMID 22000802.
- 1 2 3 4 5 Wrabl JO, Grishin NV (1 January 2004). "Gaps in structurally similar proteins: towards improvement of multiple sequence alignment". Proteins. 54 (1): 71–87. doi:10.1002/prot.10508. PMID 14705025. S2CID 20474119.
Further reading
- Taylor WR, Munro RE (1997). "Multiple sequence threading: conditional gap placement". Fold Des. 2 (4): S33-9. doi:10.1016/S1359-0278(97)00061-8. PMID 9269566.
- Taylor WR (1996). "A non-local gap-penalty for profile alignment". Bull Math Biol. 58 (1): 1–18. doi:10.1007/BF02458279. PMID 8819751. S2CID 189884646.
- Vingron M, Waterman MS (1994). "Sequence alignment and penalty choice. Review of concepts, case studies and implications". J Mol Biol. 235 (1): 1–12. doi:10.1016/S0022-2836(05)80006-3. PMID 8289235.
- Panjukov VV (1993). "Finding steady alignments: similarity and distance". Comput Appl Biosci. 9 (3): 285–90. doi:10.1093/bioinformatics/9.3.285. PMID 8324629.
- Alexandrov NN (1992). "Local multiple alignment by consensus matrix". Comput Appl Biosci. 8 (4): 339–45. doi:10.1093/bioinformatics/8.4.339. PMID 1498689.
- Hein J (1989). "A new method that simultaneously aligns and reconstructs ancestral sequences for any number of homologous sequences, when the phylogeny is given". Mol Biol Evol. 6 (6): 649–68. doi:10.1093/oxfordjournals.molbev.a040577. PMID 2488477.
- Henneke CM (1989). "A multiple sequence alignment algorithm for homologous proteins using secondary structure information and optionally keying alignments to functionally important sites". Comput Appl Biosci. 5 (2): 141–50. doi:10.1093/bioinformatics/5.2.141. PMID 2751764.
- Reich JG, Drabsch H, Daumler A (1984). "On the statistical assessment of similarities in DNA sequences". Nucleic Acids Res. 12 (13): 5529–43. doi:10.1093/nar/12.13.5529. PMC 318937. PMID 6462914.