NETtalk is an artificial neural network. It is the result of research carried out in the mid-1980s by Terrence Sejnowski and Charles Rosenberg. The intent behind NETtalk was to construct simplified models that might shed light on the complexity of learning human level cognitive tasks, and their implementation as a connectionist model that could also learn to perform a comparable task. The authors trained it in two ways, once by Boltzmann machine and once by backpropagation.[1]
NETtalk is a program that learns to pronounce written English text by being shown text as input and matching phonetic transcriptions for comparison.[2][3]
The network was trained on a large amount of English words and their corresponding pronunciations, and is able to generate pronunciations for unseen words with a high level of accuracy. The success of the NETtalk network inspired further research in the field of pronunciation generation and speech synthesis and demonstrated the potential of neural networks for solving complex NLP problems. The output of the network was a stream of phonemes, which fed into DECtalk to produce audible speech, It achieved popular success, appearing on the Today show.[4] The development process was described in a 1993 interview. It took three months to create the training dataset, but only a few days to train the network.[5]
Architecture
The network had three layers and 18,629 adjustable weights, large by the standards of 1986. There were worries that it would overfit the dataset, but it was trained successfully. The dataset was a 20,000-word subset of the Brown Corpus, with manually annotated phoneme and stress for each letter.[4]
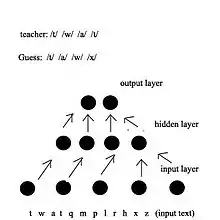
The input of the network has 203 units, divided into 7 groups of 29 units each. Each group is a one-hot encoding of one character. There are 29 possible characters: 26 letters, comma, period, and word boundary (whitespace).
The hidden layer has 80 units.
The output has 26 units. 21 units encode for articulatory features (point of articulation, voicing, vowel height, etc.) of phonemes, and 5 units encode for stress and syllable boundaries.
Achievements and limitations
NETtalk was created to explore the mechanisms of learning to correctly pronounce English text. The authors note that learning to read involves a complex mechanism involving many parts of the human brain. NETtalk does not specifically model the image processing stages and letter recognition of the visual cortex. Rather, it assumes that the letters have been pre-classified and recognized, and these letter sequences comprising words are then shown to the neural network during training and during performance testing. It is NETtalk's task to learn proper associations between the correct pronunciation with a given sequence of letters based on the context in which the letters appear. In other words, NETtalk learns to use the letters around the currently pronounced phoneme that provide cues as to its intended phonemic mapping.
References
- ↑ Sejnowski, Terrence J., and Charles R. Rosenberg. "Parallel networks that learn to pronounce English text." Complex systems 1.1 (1987): 145-168.
- ↑ Thierry Dutoit (30 November 2001). An Introduction to Text-to-Speech Synthesis. Springer Science & Business Media. pp. 123–. ISBN 978-1-4020-0369-1.
- ↑ Hinton, Geoffrey (1991). Connectionist Symbol Processing (First ed.). The MIT Press. pp. 161–163. ISBN 0-262-58106-X.
- 1 2 Sejnowski, Terrence J. (2018). The deep learning revolution. Cambridge, Massachusetts London, England: The MIT Press. ISBN 978-0-262-03803-4.
- ↑ Talking Nets: An Oral History of Neural Networks. The MIT Press. 2000-02-28. ISBN 978-0-262-26715-1.