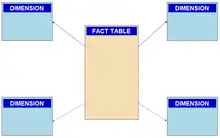
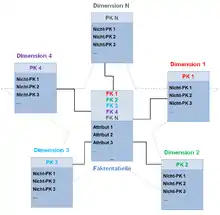
In computing, the star schema or star model is the simplest style of data mart schema and is the approach most widely used to develop data warehouses and dimensional data marts.[1] The star schema consists of one or more fact tables referencing any number of dimension tables. The star schema is an important special case of the snowflake schema, and is more effective for handling simpler queries.[2]
The star schema gets its name from the physical model's[3] resemblance to a star shape with a fact table at its center and the dimension tables surrounding it representing the star's points.
Model
The star schema separates business process data into facts, which hold the measurable, quantitative data about a business, and dimensions which are descriptive attributes related to fact data. Examples of fact data include sales price, sale quantity, and time, distance, speed and weight measurements. Related dimension attribute examples include product models, product colors, product sizes, geographic locations, and salesperson names.
A star schema that has many dimensions is sometimes called a centipede schema.[4] Having dimensions of only a few attributes, while simpler to maintain, results in queries with many table joins and makes the star schema less easy to use.
Fact tables
Fact tables record measurements or metrics for a specific event. Fact tables generally consist of numeric values, and foreign keys to dimensional data where descriptive information is kept.[4] Fact tables are designed to a low level of uniform detail (referred to as "granularity" or "grain"), meaning facts can record events at a very atomic level. This can result in the accumulation of a large number of records in a fact table over time. Fact tables are defined as one of three types:
- Transaction fact tables record facts about a specific event (e.g., sales events)
- Snapshot fact tables record facts at a given point in time (e.g., account details at month end)
- Accumulating snapshot tables record aggregate facts at a given point in time (e.g., total month-to-date sales for a product)
Fact tables are generally assigned a surrogate key to ensure each row can be uniquely identified. This key is a simple primary key.
Dimension tables
Dimension tables usually have a relatively small number of records compared to fact tables, but each record may have a very large number of attributes to describe the fact data. Dimensions can define a wide variety of characteristics, but some of the most common attributes defined by dimension tables include:
- Time dimension tables describe time at the lowest level of time granularity for which events are recorded in the star schema
- Geography dimension tables describe location data, such as country, state, or city
- Product dimension tables describe products
- Employee dimension tables describe employees, such as sales people
- Range dimension tables describe ranges of time, dollar values or other measurable quantities to simplify reporting
Dimension tables are generally assigned a surrogate primary key, usually a single-column integer data type, mapped to the combination of dimension attributes that form the natural key.
Benefits
Star schemas are denormalized, meaning the typical rules of normalization applied to transactional relational databases are relaxed during star-schema design and implementation. The benefits of star-schema denormalization are:
- Simpler queries – star-schema join-logic is generally simpler than the join logic required to retrieve data from a highly normalized transactional schema.
- Simplified business reporting logic – when compared to highly normalized schemas, the star schema simplifies common business reporting logic, such as period-over-period and as-of reporting.
- Query performance gains – star schemas can provide performance enhancements for read-only reporting applications when compared to highly normalized schemas.
- Fast aggregations – the simpler queries against a star schema can result in improved performance for aggregation operations.
- Feeding cubes – star schemas are used by all OLAP systems to build proprietary OLAP cubes efficiently; in fact, most major OLAP systems provide a ROLAP mode of operation which can use a star schema directly as a source without building a proprietary cube structure.
Example
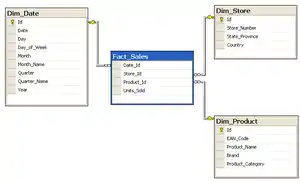
Consider a database of sales, perhaps from a store chain, classified by date, store and product. The image of the schema to the right is a star schema version of the sample schema provided in the snowflake schema article.
Fact_Sales is the fact table and there are three dimension tables Dim_Date, Dim_Store and Dim_Product.
Each dimension table has a primary key on its Id column, relating to one of the columns (viewed as rows in the example schema) of the Fact_Sales table's three-column (compound) primary key (Date_Id, Store_Id, Product_Id). The non-primary key Units_Sold column of the fact table in this example represents a measure or metric that can be used in calculations and analysis. The non-primary key columns of the dimension tables represent additional attributes of the dimensions (such as the Year of the Dim_Date dimension).
For example, the following query answers how many TV sets have been sold, for each brand and country, in 1997:
SELECT
P.Brand,
S.Country AS Countries,
SUM(F.Units_Sold)
FROM Fact_Sales F
INNER JOIN Dim_Date D ON (F.Date_Id = D.Id)
INNER JOIN Dim_Store S ON (F.Store_Id = S.Id)
INNER JOIN Dim_Product P ON (F.Product_Id = P.Id)
WHERE D.Year = 1997 AND P.Product_Category = 'tv'
GROUP BY
P.Brand,
S.Country
See also
References
- ↑ Dedić, N. and Stanier C., 2016., "An Evaluation of the Challenges of Multilingualism in Data Warehouse Development" in 18th International Conference on Enterprise Information Systems - ICEIS 2016, p. 196.
- ↑ DWH Schemas, 2009, archived from the original on 16 July 2010
- ↑ ", p. 708
- 1 2 Ralph Kimball and Margy Ross, The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling (Second Edition), p. 393