TRACE is a connectionist model of speech perception, proposed by James McClelland and Jeffrey Elman in 1986.[1] It is based on a structure called "the TRACE," a dynamic processing structure made up of a network of units, which performs as the system's working memory as well as the perceptual processing mechanism.[2] TRACE was made into a working computer program for running perceptual simulations. These simulations are predictions about how a human mind/brain processes speech sounds and words as they are heard in real time.
Inspiration
TRACE was created during the formative period of connectionism, and was included as a chapter in Parallel Distributed Processing: Explorations in the Microstructures of Cognition.[3] The researchers found that certain problems regarding speech perception could be conceptualized in terms of a connectionist interactive activation model. The problems were that
(1) speech is extended in time
(2) the sounds of speech (phonemes) overlap with each other
(3) the articulation of a speech sound is affected by the sounds that come before and after it, and
(4) there is natural variability in speech (e.g. foreign accent) as well as noise in the environment (e.g. busy restaurant).
Each of these causes the speech signal to be complex and often ambiguous, making it difficult for the human mind/brain to decide what words it is really hearing. In very simple terms, an interactive activation model solves this problem by placing different kinds of processing units (phonemes, words) in isolated layers, allowing activated units to pass information between layers, and having units within layers compete with one another, until the “winner” is considered “recognized” by the model.
Key findings
"TRACE was the first model that instantiated the activation of multiple word candidates that match any part of the speech input."[4] A simulation of speech perception involves presenting the TRACE computer program with mock speech input, running the program, and generating a result. A successful simulation indicates that the result is found to be meaningfully similar to how people process speech.
Time-course of word recognition
It is generally accepted in psycholinguistics that (1) when the beginning of a word is heard, a set of words that share the same initial sound become activated in memory,[5] (2) the words that are activated compete with each other while more and more of the word is heard,[6] (3) at some point, due to both the auditory input and the lexical competition, one word is recognized.[1]
For example, a listener hears the beginning of bald, and the words bald, ball, bad, bill become active in memory. Then, soon after, only bald and ball remain in competition (bad, bill have been eliminated because the vowel sound doesn't match the input). Soon after, bald is recognized. TRACE simulates this process by representing the temporal dimension of speech, allowing words in the lexicon to vary in activation strength, and by having words compete during processing. Figure 1 shows a line graph of word activation in a simple TRACE simulation.

Lexical effect on phoneme perception
If an ambiguous speech sound is spoken that is exactly in between /t/ and /d/, the hearer may have difficulty deciding what it is. But, if that same ambiguous sound is heard at the end of a word like woo/?/ (where ? is the ambiguous sound), then the hearer will more likely perceive the sound as a /d/. This probably occurs because "wood" is a word but "woot" is not. An ambiguous phoneme presented in a lexical context will be perceived as consistent with the surrounding lexical context. This perceptual effect is known as the Ganong effect.[7] TRACE reliably simulates this, and can explain it in relatively simple terms. Essentially, the lexical unit which has become activated by the input (i.e. wood) feeds back activation to the phoneme layer, boosting the activation of its constituent phonemes (i.e. /d/), thus resolving the ambiguity.
Lexical basis of segmentation
Speakers usually don't leave pauses in between words when speaking, yet listeners seem to have no difficulty hearing speech as a sequence of words. This is known as the segmentation problem, and is one of the oldest problems in the psychology of language. TRACE proposed the following solution, backed up by simulations. When words become activated and recognized, this reveals the location of word boundaries. Stronger word activation leads to greater confidence about word boundaries, which informs the hearer of where to expect the next word to begin.[1]
Process
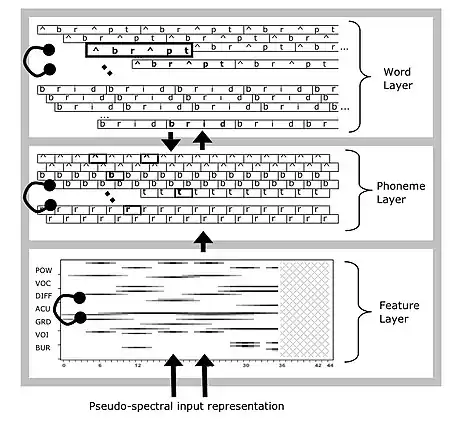
The TRACE model is a connectionist network with an input layer and three processing layers: pseudo-spectra (feature), phoneme and word. Figure 2 shows a schematic diagram of TRACE. There are three types of connectivity: (1) feedforward excitatory connections from input to features, features to phonemes, and phonemes to words; (2) lateral (i.e., within layer) inhibitory connections at the feature, phoneme and word layers; and (3) top-down feedback excitatory connections from words to phonemes. The input to TRACE works as follows. The user provides a phoneme sequence that is converted into a multi-dimensional feature vector. This is an approximation of acoustic spectra extended in time. The input vector is revealed a little at a time to simulate the temporal nature of speech. As each new chunk of input is presented, this sends activity along the network connections, changing the activation values in the processing layers. Features activate phoneme units, and phonemes activate word units. Parameters govern the strength of the excitatory and inhibitory connections, as well as many other processing details. There is no specific mechanism that determines when a word or a phoneme has been recognized. If simulations are being compared to reaction time data from a perceptual experiment (e.g. lexical decision), then typically an activation threshold is used. This allows for the model behavior to be interpreted as recognition, and a recognition time to be recorded as the number of processing cycles that have elapsed. For deeper understanding of TRACE processing dynamics, readers are referred to the original publication[1] and to a TRACE software tool that runs simulations with a graphical user interface.
Criticism
Modularity of mind debate
TRACE’s relevance to the modularity debate has recently been brought to the fore by Norris, Cutler and McQueen’s (2001) report on the Merge (?) model of speech perception.[8] While it shares a number of features with TRACE, a key difference is the following. While TRACE permits word units to feedback activation to the phoneme level, Merge restricts its processing to feed-forward connections. In the terms of this debate, TRACE is considered to violate the principle of information encapsulation, central to modularity, when it permits a later stage of processing (words) to send information to an earlier stage (phonemes). Merge advocates for modularity by arguing that the same class of perceptual phenomena that is accounted for in TRACE can be explained in a connectionist architecture that does not include feedback connections. Norris et al. point out that when two theories can explain the same phenomenon, parsimony dictates that the simpler theory is preferable.
Applications
Speech and language therapy
Models of language processing can be used to conceptualize the nature of impairment in persons with speech and language disorder. For example, it has been suggested that language deficits in expressive aphasia may be caused by excessive competition between lexical units, thus preventing any word from becoming sufficiently activated.[9] Arguments for this hypothesis consider that mental dysfunction can be explained by slight perturbation of the network model's processing. This emerging line of research incorporates a wide range of theories and models, and TRACE represents just one piece of a growing puzzle.
Distinction from speech recognition software
Psycholinguistic models of speech perception, e.g. TRACE, must be distinguished from computer speech recognition tools. The former are psychological theories about how the human mind/brain processes information. The latter are engineered solutions for converting an acoustic signal into text. Historically, the two fields have had little contact, but this is beginning to change.[10]
Influence
TRACE’s influence in the psychology literature can be assessed by the number of articles that cite it. There are 345 citations of McClelland and Elman (1986) in the PsycINFO database. Figure 3 shows the distribution of those citations over the years since publication. The figure suggests that interest in TRACE grew significantly in 2001, and has remained strong, with about 30 citations per year.

See also
- Motor theory of speech perception (rival theory)
- Cohort model (rival theory)
References
- 1 2 3 4 McClelland, J.L., & Elman, J.L. (1986)
- ↑ McClelland, James; Elman, Jeffrey (January 1986). "The TRACE Model of Speech Perception". Cognitive Psychology. 18 (1): 1–86. doi:10.1016/0010-0285(86)90015-0. PMID 3753912. S2CID 7428866.
- ↑ McClelland, J.L., D.E. Rumelhart and the PDP Research Group (1986). Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Volume 2: Psychological and Biological Models, Cambridge, Massachusetts: MIT Press
- ↑ Weber, Andrea; Scharenborg, Odette (2012-05-01). "Models of spoken-word recognition". Wiley Interdisciplinary Reviews: Cognitive Science. 3 (3): 387–401. doi:10.1002/wcs.1178. hdl:11858/00-001M-0000-0012-29E4-5. ISSN 1939-5086. PMID 26301470.
- ↑ Marslen-Wilson, W.; Tyler, L. K. (1980). "The temporal structure of spoken language understanding". Cognition. 8 (1): 1–71. CiteSeerX 10.1.1.299.7676. doi:10.1016/0010-0277(80)90015-3. PMID 7363578. S2CID 11708426.
- ↑ Luce, P. A.; Pisoni, D. B. (1998). "Recognizing spoken words: The neighborhood activation model". Ear and Hearing. 19 (1): 1–36. doi:10.1097/00003446-199802000-00001. PMC 3467695. PMID 9504270.
- ↑ Ganong, W. F. (1980). Phonetic categorization in auditory perception. Journal of Experimental Psychology: Human Perception and Performance, 6, 110–125.
- ↑ Norris, D.; McQueen, J. M.; Cutler, A. (2000). "Merging information in speech recognition: Feedback is never necessary". Behavioral and Brain Sciences. 23 (3): 299–370. doi:10.1017/s0140525x00003241. hdl:11858/00-001M-0000-0013-3790-1. PMID 11301575. S2CID 32291239.
- ↑ Self-organizing dynamics of lexical access in normals and aphasics. McNellis, Mark G.; Blumstein, Sheila E.; Journal of Cognitive Neuroscience, Vol 13(2), Feb 2001. pp. 151-170.
- ↑ Scharenborg, O.; Norris, D.; ten Bosch, L.; McQueen, J.M. (2005). "How should a speech recognizer work?". Cognitive Science. 29 (6): 867–918. doi:10.1207/s15516709cog0000_37. hdl:11858/00-001M-0000-0013-1E5D-C. PMID 21702797.
External links
- jTRACE - A Java reimplementation of the TRACE model. Open-source platform-independent software. Page also includes download of an earlier c language implementation of TRACE.