 Trino UI Version 358 | |
| Original author(s) | Martin Traverso, Dain Sundstrom, David Phillips, Eric Hwang |
|---|---|
| Repository | Trino Repository |
| Written in | Java |
| Operating system | Cross-platform |
| Standard(s) | ANSI SQL, JDBC |
| Type | Data Warehouse |
| License | Apache License 2.0 |
| Website | trino |
Trino is an open-source distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources.[1] Trino can query datalakes that contain open column-oriented data file formats like ORC or Parquet[2][3] residing on different storage systems like HDFS, AWS S3, Google Cloud Storage, or Azure Blob Storage[4] using the Hive[2] and Iceberg[3] table formats. Trino also has the ability to run federated queries that query tables in different data sources such as MySQL, PostgreSQL, Cassandra, Kafka, MongoDB and Elasticsearch.[5] Trino is released under the Apache License.[6]
History
In January 2019, the original creators of Presto, Martin Traverso, Dain Sundstrom, and David Phillips, created a fork of the Presto project. They initially kept the name Presto and used the PrestoSQL web handle to distinguish it from the original PrestoDB project. Simultaneously, they announced the Presto Software Foundation. The foundation is a not-for-profit organization dedicated to the advancement of the Presto open source distributed SQL query engine.[7][8]
In December 2020, PrestoSQL was rebranded as Trino. The Trino Software Foundation, code base, and all other PrestoSQL assets were renamed as part of the rebrand.[9]
Presto and Trino were originally designed and developed by Martin, Dain, David, and Eric Hwang at Facebook to allow data analysts to run interactive queries on its large data warehouse in Apache Hadoop. Trino shares the first six years of development with the Presto project.[10][11] To learn more about the earlier history of Trino, you can reference the Presto history section.
In October 2022, Amazon announced that Amazon Athena will use Trino engine.[12]
Architecture
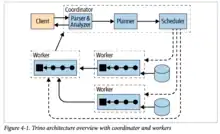
Trino is written in Java.[14] It runs on a cluster of servers that contains two types of nodes, a coordinator and a worker.[13]
- The coordinator is responsible for parsing, analyzing, optimizing, planning, and scheduling a query submitted by a client. The coordinator interacts with the service provider interface (SPI) to obtain the available tables, table statistics, and other information needed to carry out its tasks.[13]
- The workers are responsible for executing the tasks and operators fed to them by the scheduler. These tasks process rows from the data sources which produce results that are returned to the coordinator and ultimately back to the client.[13]
Trino adheres to the ANSI SQL[4] standard and includes various parts of the following ANSI specifications: SQL-92, SQL:1999, SQL:2003, SQL:2008, SQL:2011, SQL:2016.
Trino supports the separation of compute and storage[4] and may be deployed both on-premises and in the cloud.[15]
Trino has a Distributed computing MPP architecture.[13] Trino first distributes work over multiple workers by running ad-hoc partitioning operations or relying on existing partitions in the data of the underlying data store. Once this data has reached the worker, the data is processed over pipelined operators carried out on multiple threads.[13]
See also
References
- ↑ "Overview — Trino 393 Documentation". trino.io. Retrieved 25 August 2022.
- 1 2 "Hive connector — Trino 393 Documentation". trino.io.
- 1 2 "Iceberg connector — Trino 393 Documentation". trino.io. Retrieved 25 August 2022.
- 1 2 3 Fuller, Matt; Moser, Manfred; Traverso, Martin (2021). "Chapter 1. Introducing Trino". Trino: The Definitive Guide. O'Reilly Media, Inc, USA. pp. 3–17. ISBN 9781098107710.
- ↑ "Connectors — Trino 393 Documentation". trino.io. Retrieved 25 August 2022.
- ↑ "trinodb/trino LICENSE". Trino. 25 August 2022. Retrieved 25 August 2022.
- ↑ "Presto Software Foundation Launches to Advance Presto Open Source Community". PRWeb. Retrieved 2019-02-01.
- ↑ "Presto's New Foundation Signals Growth for the Big Data SQL Engine". The New Stack. 2019-01-31. Retrieved 2019-02-01.
- ↑ Traverso, Martin; Sundstrom, Dain; Phillips, David (27 December 2020). "We're rebranding PrestoSQL as Trino". trino.io. Retrieved 7 September 2021.
- ↑ "Contributors to trinodb/trino". GitHub. Retrieved 20 September 2021.
- ↑ "Contributors to prestodb/presto". GitHub. Retrieved 20 September 2021.
- ↑ "Amazon Athena announces upgraded query engine". AWS. October 13, 2022.
- 1 2 3 4 5 6 Fuller, Matt; Moser, Manfred; Traverso, Martin (2021). "Chapter 4. Trino Architecture". Trino: The Definitive Guide. O'Reilly Media, Inc, USA. pp. 43–72. ISBN 9781098107710.
- ↑ Fuller, Matt; Moser, Manfred; Traverso, Martin (2021). "Chapter 2. Installing and Configuring Trino". Trino: The Definitive Guide. O'Reilly Media, Inc, USA. pp. 19–24. ISBN 9781098107710.
- ↑ Fuller, Matt; Moser, Manfred; Traverso, Martin (2021). "Chapter 13. Real-World Examples". Trino: The Definitive Guide. O'Reilly Media, Inc, USA. pp. 267–272. ISBN 9781098107710.