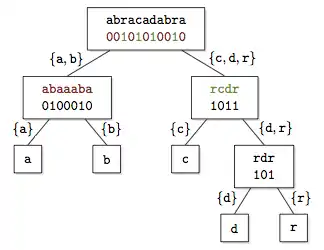
The Wavelet Tree is a succinct data structure to store strings in compressed space. It generalizes the and operations defined on bitvectors to arbitrary alphabets.


Originally introduced to represent compressed suffix arrays,[1] it has found application in several contexts.[2][3] The tree is defined by recursively partitioning the alphabet into pairs of subsets; the leaves correspond to individual symbols of the alphabet, and at each node a bitvector stores whether a symbol of the string belongs to one subset or the other.
The name derives from an analogy with the wavelet transform for signals, which recursively decomposes a signal into low-frequency and high-frequency components.
Properties
Let be a finite alphabet with . By using succinct dictionaries in the nodes, a string can be stored in , where is the order-0 empirical entropy of .






If the tree is balanced, the operations , , and can be supported in time.


Access operation
A wavelet tree contains a bitmap representation of a string. If we know the alphabet set, then the exact string can be inferred by tracking bits down the tree. To find the letter at ith position in the string :-
Algorithm access
Input:
- The position i in the string of which we want to know the letter, starting at 1.
- The top node W of the wavelet tree that represents the string
Output: The letter at position i
if W.isLeafNode return W.letter
if W.bitvector[i] = 0 return access(i - rank(W.bitvector, i), W.left)
else return access(rank(W.bitvector, i), W.right)
- "←" denotes assignment. For instance, "largest ← item" means that the value of largest changes to the value of item.
- "return" terminates the algorithm and outputs the following value.
In this context, the rank of a position in a bitvector is the number of ones that appear in the first positions of . Because the rank can be calculated in O(1) by using succinct dictionaries, any S[i] in string S can be accessed in [3] time, as long as the tree is balanced.


Extensions
Several extensions to the basic structure have been presented in the literature. To reduce the height of the tree, multiary nodes can be used instead of binary.[2] The data structure can be made dynamic, supporting insertions and deletions at arbitrary points of the string; this feature enables the implementation of dynamic FM-indexes.[4] This can be further generalized, allowing the update operations to change the underlying alphabet: the Wavelet Trie[5] exploits the trie structure on an alphabet of strings to enable dynamic tree modifications.
Further reading
- Wavelet Trees. A blog post describing the construction of a wavelet tree, with examples.
References
- ↑ R. Grossi, A. Gupta, and J. S. Vitter, High-order entropy-compressed text indexes, Proceedings of the 14th Annual SIAM/ACM Symposium on Discrete Algorithms (SODA), January 2003, 841-850.
- 1 2 P. Ferragina, R. Giancarlo, G. Manzini, The myriad virtues of Wavelet Trees, Information and Computation, Volume 207, Issue 8, August 2009, Pages 849-866
- ↑ H.-L. Chan, W.-K. Hon, T.-W. Lam, and K. Sadakane, Compressed Indexes for dynamic text collections, ACM Transactions on Algorithms, 3(2), 2007
- ↑ R. Grossi and G. Ottaviano, The Wavelet Trie: maintaining an indexed sequence of strings in compressed space, In Proceedings of the 31st Symposium on the Principles of Database Systems (PODS), 2012
External links
 Media related to Wavelet Tree at Wikimedia Commons
Media related to Wavelet Tree at Wikimedia Commons