| Sa | |
|---|---|
 | |
| Example glyphs | |
| Meitei | |
| Bengali-Assamese | |
| Tibetan | |
| Tamil | ஸ |
| Thai | ส |
| Malayalam | സ |
| Sinhala | ස |
| Ashoka Brahmi | |
| Devanagari | |
| Cognates | |
| Hebrew | ס |
| Greek | Ξ |
| Cyrillic | Ѯ |
| Properties | |
| Phonemic representation | /s/ |
| IAST transliteration | s S |
| ISCII code point | D7 (215) |
| Indic letters | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Consonants | |||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||
| Vowels | |||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||
| Other marks | |||||||||||||||||||||||||||||||||||||||||||||||||
| Punctuation | |||||||||||||||||||||||||||||||||||||||||||||||||
Sa is a consonant of Indic abugidas. In modern Indic scripts, Sa is derived from the early "Ashoka" Brahmi letter ![]() after having gone through the Gupta letter
after having gone through the Gupta letter ![]() .
.
Āryabhaṭa numeration
Aryabhata used Devanagari letters for numbers, very similar to the Greek numerals, even after the invention of Indian numerals. The values of the different forms of स are:[1]
- स [sə] = 90 (९०)
- सि [sɪ] = 9,000 (९ ०००)
- सु [sʊ] = 900,000 (९ ०० ०००)
- सृ [sri] = 90,000,000 (९ ०० ०० ०००)
- सॢ [slə] = 9×109 (९×१०९)
- से [se] = 9×1011 (९×१०११)
- सै [sɛː] = 9×1013 (९×१०१३)
- सो [soː] = 9×1015 (९×१०१५)
- सौ [sɔː] = 9×1017 (९×१०१७)
Historic Sa
There are three different general early historic scripts - Brahmi and its variants, Kharoṣṭhī, and Tocharian, the so-called slanting Brahmi. Sa as found in standard Brahmi, ![]() was a simple geometric shape, with variations toward more flowing forms by the Gupta
was a simple geometric shape, with variations toward more flowing forms by the Gupta ![]() . The Tocharian Sa
. The Tocharian Sa ![]() had an alternate Fremdzeichen form,
had an alternate Fremdzeichen form, ![]() . The third form of sa, in Kharoshthi (
. The third form of sa, in Kharoshthi (![]() ) was probably derived from Aramaic separately from the Brahmi letter.
) was probably derived from Aramaic separately from the Brahmi letter.
Brahmi Sa
The Brahmi letter ![]() , Sa, is probably derived from the altered Aramaic Samekh
, Sa, is probably derived from the altered Aramaic Samekh ![]() , and is thus related to the modern Greek Xi.[2] Several identifiable styles of writing the Brahmi Sa can be found, most associated with a specific set of inscriptions from an artifact or diverse records from an historic period.[3] As the earliest and most geometric style of Brahmi, the letters found on the Edicts of Ashoka and other records from around that time are normally the reference form for Brahmi letters, with vowel marks not attested until later forms of Brahmi back-formed to match the geometric writing style.
, and is thus related to the modern Greek Xi.[2] Several identifiable styles of writing the Brahmi Sa can be found, most associated with a specific set of inscriptions from an artifact or diverse records from an historic period.[3] As the earliest and most geometric style of Brahmi, the letters found on the Edicts of Ashoka and other records from around that time are normally the reference form for Brahmi letters, with vowel marks not attested until later forms of Brahmi back-formed to match the geometric writing style.
| Ashoka (3rd-1st c. BCE) | Girnar (~150 BCE) | Kushana (~150-250 CE) | Gujarat (~250 CE) | Gupta (~350 CE) |
|---|---|---|---|---|
Tocharian Sa
The Tocharian letter ![]() is derived from the Brahmi
is derived from the Brahmi ![]() , and has an alternate Fremdzeichen form
, and has an alternate Fremdzeichen form ![]() used in conjuncts and as an alternate representation of Sä.
used in conjuncts and as an alternate representation of Sä.
| Sa | Sā | Si | Sī | Su | Sū | Sr | Sr̄ | Se | Sai | So | Sau | Sä | Fremdzeichen |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Kharoṣṭhī Sa
The Kharoṣṭhī letter ![]() is generally accepted as being derived from the altered Aramaic Samekh
is generally accepted as being derived from the altered Aramaic Samekh ![]() , and is thus related to Xi, in addition to the Brahmi Sa.[2]
, and is thus related to Xi, in addition to the Brahmi Sa.[2]
Devanagari Sa
| Devanāgarī |
|---|
 |
Sa (स) is a consonant of the Devanagari abugida. It ultimately arose from the Brahmi letter ![]() , after having gone through the Gupta letter
, after having gone through the Gupta letter ![]() . Letters that derive from it are the Gujarati letter સ, and the Modi letter 𑘭.
. Letters that derive from it are the Gujarati letter સ, and the Modi letter 𑘭.
Devanagari-using Languages
In all languages, स is pronounced as [sə] or [s] when appropriate. Like all Indic scripts, Devanagari uses vowel marks attached to the base consonant to override the inherent /ə/ vowel:
| Sa | Sā | Si | Sī | Su | Sū | Sr | Sr̄ | Sl | Sl̄ | Se | Sai | So | Sau | S |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| स | सा | सि | सी | सु | सू | सृ | सॄ | सॢ | सॣ | से | सै | सो | सौ | स् |
Conjuncts with स

Devanagari exhibits conjunct ligatures, as is common in Indic scripts. In modern Devanagari texts, most conjuncts are formed by reducing the letter shape to fit tightly to the following letter, usually by dropping a character's vertical stem, sometimes referred to as a "half form". Some conjunct clusters are always represented by a true ligature, instead of a shape that can be broken into constituent independent letters. Vertically stacked conjuncts are ubiquitous in older texts, while only a few are still used routinely in modern Devanagari texts. The use of ligatures and vertical conjuncts may vary across languages using the Devanagari script, with Marathi in particular preferring the use of half forms where texts in other languages would show ligatures and vertical stacks.[4]
Ligature conjuncts of स
True ligatures are quite rare in Indic scripts. The most common ligated conjuncts in Devanagari are in the form of a slight mutation to fit in context or as a consistent variant form appended to the adjacent characters. Those variants include Na and the Repha and Rakar forms of Ra. Nepali and Marathi texts use the "eyelash" Ra half form ![]() for an initial "R" instead of repha.
for an initial "R" instead of repha.
- Repha र্ (r) + स (sa) gives the ligature rsa: note

- Eyelash र্ (r) + स (sa) gives the ligature rsa:
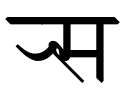
- स্ (s) + rakar र (ra) gives the ligature sra:

Stacked conjuncts of स
Vertically stacked ligatures are the most common conjunct forms found in Devanagari text. Although the constituent characters may need to be stretched and moved slightly in order to stack neatly, stacked conjuncts can be broken down into recognizable base letters, or a letter and an otherwise standard ligature.
- छ্ (ch) + स (sa) gives the ligature chsa:

- ढ্ (ḍʱ) + स (sa) gives the ligature ḍʱsa:

- ड্ (ḍ) + स (sa) gives the ligature ḍsa:

- द্ (d) + स (sa) gives the ligature dsa:

- ङ্ (ŋ) + स (sa) gives the ligature ŋsa:

- Repha र্ (r) + स্ (s) + व (va) gives the ligature rsva:

- स্ (s) + ब (ba) gives the ligature sba:

- स্ (s) + च (ca) gives the ligature sca:

- स্ (s) + ज (ja) gives the ligature sja:

- स্ (s) + ज্ (j) + ञ (ña) gives the ligature sjña:

- स্ (s) + ल (la) gives the ligature sla:

- स্ (s) + न (na) gives the ligature sna:

- स্ (s) + ञ (ña) gives the ligature sña:

- स্ (s) + व (va) gives the ligature sva:

- ठ্ (ṭh) + स (sa) gives the ligature ṭhsa:

- ट্ (ṭ) + स (sa) gives the ligature ṭsa:

Bengali Sa
The Bengali script স is derived from the Siddhaṃ ![]() , and is marked by a similar horizontal head line, but less geometric shape, than its Devanagari counterpart, स. The inherent vowel of Bengali consonant letters is /ɔ/, so the bare letter স will sometimes be transliterated as "so" instead of "sa". Adding okar, the "o" vowel mark, gives a reading of /so/.
Like all Indic consonants, স can be modified by marks to indicate another (or no) vowel than its inherent "a".
, and is marked by a similar horizontal head line, but less geometric shape, than its Devanagari counterpart, स. The inherent vowel of Bengali consonant letters is /ɔ/, so the bare letter স will sometimes be transliterated as "so" instead of "sa". Adding okar, the "o" vowel mark, gives a reading of /so/.
Like all Indic consonants, স can be modified by marks to indicate another (or no) vowel than its inherent "a".
| sa | sā | si | sī | su | sū | sr | sr̄ | se | sai | so | sau | s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| স | সা | সি | সী | সু | সূ | সৃ | সৄ | সে | সৈ | সো | সৌ | স্ |
স in Bengali-using languages
স is used as a basic consonant character in all of the major Bengali script orthographies, including Bengali and Assamese.
Conjuncts with স
Bengali স exhibits conjunct ligatures, as is common in Indic scripts, with a tendency towards stacked ligatures.[5]
- ক্ (k) + স (sa) gives the ligature ksa:

- প্ (p) + স (sa) gives the ligature psa:

- র্ (r) + স (sa) gives the ligature rsa, with the repha prefix:

- স্ (s) + ক (ka) gives the ligature ska:

- স্ (s) + খ (kha) gives the ligature skha:

- স্ (s) + ক্ (k) + র (ra) gives the ligature skra, with the ra phala suffix:

- স্ (s) + ল (la) gives the ligature sla:

- স্ (s) + ম (ma) gives the ligature sma:

- স্ (s) + ন (na) gives the ligature sna:

- স্ (s) + প (pa) gives the ligature spa:

- স্ (s) + ফ (pha) gives the ligature spha:

- স্ (s) + প্ (p) + ল (la) gives the ligature spla:

- স্ (s) + র (ra) gives the ligature sra, with the ra phala suffix:

- স্ (s) + ত (ta) gives the ligature sta:

- স্ (s) + থ (tha) gives the ligature stha:

- স্ (s) + থ্ (th) + য (ya) gives the ligature sthya, with the ya phala suffix:

- স্ (s) + ত্ (t) + র (ra) gives the ligature stra, with the ra phala suffix:

- স্ (s) + ট (ṭa) gives the ligature sṭa:

- স্ (s) + ট্ (ṭ) + র (ra) gives the ligature sṭra, with the ra phala suffix:

- স্ (s) + ত্ (t) + ব (va) gives the ligature stva, with the va phala suffix:

- স্ (s) + ত্ (t) + য (ya) gives the ligature stya, with the ya phala suffix:

- স্ (s) + ব (va) gives the ligature sva, with the va phala suffix:

- স্ (s) + য (ya) gives the ligature sya, with the ya phala suffix:

- ত্ (t) + স (sa) gives the ligature tsa:

Gujarati Sa

Sa (સ) is the thirty-second consonant of the Gujarati abugida. It is derived from the Devanagari Sa ![]() with the top bar (shiro rekha) removed, and ultimately the Brahmi letter
with the top bar (shiro rekha) removed, and ultimately the Brahmi letter ![]() .
.
Gujarati-using Languages
The Gujarati script is used to write the Gujarati and Kutchi languages. In both languages, સ is pronounced as [sə] or [s] when appropriate. Like all Indic scripts, Gujarati uses vowel marks attached to the base consonant to override the inherent /ə/ vowel:
| Sa | Sā | Si | Sī | Su | Sū | Sr | Sl | Sr̄ | Sl̄ | Sĕ | Se | Sai | Sŏ | So | Sau | S |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
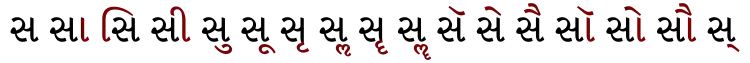 | ||||||||||||||||
| Gujarati Sa syllables, with vowel marks in red. | ||||||||||||||||
Conjuncts with સ

Gujarati સ exhibits conjunct ligatures, much like its parent Devanagari Script. Most Gujarati conjuncts can only be formed by reducing the letter shape to fit tightly to the following letter, usually by dropping a character's vertical stem, sometimes referred to as a "half form". A few conjunct clusters can be represented by a true ligature, instead of a shape that can be broken into constituent independent letters, and vertically stacked conjuncts can also be found in Gujarati, although much less commonly than in Devanagari. True ligatures are quite rare in Indic scripts. The most common ligated conjuncts in Gujarati are in the form of a slight mutation to fit in context or as a consistent variant form appended to the adjacent characters. Those variants include Na and the Repha and Rakar forms of Ra.
- ર્ (r) + સ (sa) gives the ligature RSa:

- સ્ (s) + ર (ra) gives the ligature SRa:

Javanese Sa
Telugu Sa
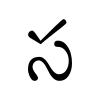

Sa (స) is a consonant of the Telugu abugida. It ultimately arose from the Brahmi letter ![]() . It is closely related to the Kannada letter ಸ. Most Telugu consonants contain a v-shaped headstroke that is related to the horizontal headline found in other Indic scripts, although headstrokes do not connect adjacent letters in Telugu. The headstroke is normally lost when adding vowel matras.
Telugu conjuncts are created by reducing trailing letters to a subjoined form that appears below the initial consonant of the conjunct. Many subjoined forms are created by dropping their headline, with many extending the end of the stroke of the main letter body to form an extended tail reaching up to the right of the preceding consonant. This subjoining of trailing letters to create conjuncts is in contrast to the leading half forms of Devanagari and Bengali letters. Ligature conjuncts are not a feature in Telugu, with the only non-standard construction being an alternate subjoined form of Ṣa (borrowed from Kannada) in the KṢa conjunct.
. It is closely related to the Kannada letter ಸ. Most Telugu consonants contain a v-shaped headstroke that is related to the horizontal headline found in other Indic scripts, although headstrokes do not connect adjacent letters in Telugu. The headstroke is normally lost when adding vowel matras.
Telugu conjuncts are created by reducing trailing letters to a subjoined form that appears below the initial consonant of the conjunct. Many subjoined forms are created by dropping their headline, with many extending the end of the stroke of the main letter body to form an extended tail reaching up to the right of the preceding consonant. This subjoining of trailing letters to create conjuncts is in contrast to the leading half forms of Devanagari and Bengali letters. Ligature conjuncts are not a feature in Telugu, with the only non-standard construction being an alternate subjoined form of Ṣa (borrowed from Kannada) in the KṢa conjunct.
Malayalam Sa
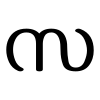
Sa (സ) is a consonant of the Malayalam abugida. It ultimately arose from the Brahmi letter ![]() , via the Grantha letter
, via the Grantha letter ![]() Sa. Like in other Indic scripts, Malayalam consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Sa. Like in other Indic scripts, Malayalam consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Conjuncts of സ
As is common in Indic scripts, Malayalam joins letters together to form conjunct consonant clusters. There are several ways in which conjuncts are formed in Malayalam texts: using a post-base form of a trailing consonant placed under the initial consonant of a conjunct, a combined ligature of two or more consonants joined together, a conjoining form that appears as a combining mark on the rest of the conjunct, the use of an explicit candrakkala mark to suppress the inherent "a" vowel, or a special consonant form called a "chillu" letter, representing a bare consonant without the inherent "a" vowel. Texts written with the modern reformed Malayalam orthography, put̪iya lipi, may favor more regular conjunct forms than older texts in paḻaya lipi, due to changes undertaken in the 1970s by the Government of Kerala.
- സ് (s) + ത (ta) gives the ligature sta:
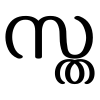
- സ് (s) + ഥ (tha) gives the ligature stha:
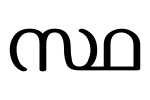
- സ് (s) + ന (na) gives the ligature sna:

- സ് (s) + പ (pa) gives the ligature spa:

- സ് (s) + മ (ma) gives the ligature sma:
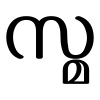
- ക് (k) + സ (sa) gives the ligature ksa:

- ത് (t) + സ (sa) gives the ligature tsa:

- പ് (p) + സ (sa) gives the ligature psa:

- സ് (s) + സ (sa) gives the ligature ssa:

Canadian Aboriginal Syllabics Se
| Canadian Aboriginal Syllabics | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||
ᓭ, ᓯ, ᓱ and ᓴ are the base characters "Se", "Si", "So" and "Sa" in the Canadian Aboriginal Syllabics. The bare consonant ᔅ (S) is a small version of the A-series letter ᓴ, although the letter ᐢ, derived from Pitman shorthand was the original bare consonant symbol for S. The character ᓭ is derived from a handwritten form of the Devanagari letter स, without the headline or vertical stem, and the forms for different vowels are derived by mirroring.[6][7] Unlike most writing systems without legacy computer encodings, complex Canadian syllabic letters are represented in Unicode with pre-composed characters, rather than with base characters and diacritical marks.
| Variant | E-series | I-series | O-series | A-series | Other | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| S + vowel | ᓭ | ᓯ | ᓱ | ᓴ | - | ||||||
| Se | Si | So | Sa | - | |||||||
| Small | - | ᣚ | ᔇ | ᔅ | ᐢ | ||||||
| - | Ojibway S | Sw | S | Algonquian S | |||||||
| S with long vowels | - | ᓰ | ᓲ | ᓳ | ᓵ | - | |||||
| - | Sī | Sō | Cree Sō | Sā | - | ||||||
| S + W-vowels | ᓶ | ᓷ | ᓸ | ᓹ | ᓼ | ᓽ | ᔀ | ᔁ | ᔋ | ||
| Swe | Cree Swe | Swi | Cree Swi | Swo | Cree Swo | Swa | Cree Swa | Naskapi Sw | |||
| S + long W-vowels | - | ᓺ | ᓻ | ᓾ | ᓿ | ᔂ | ᔄ | ᔃ | - | ||
| - | Swī | Cree Swī | Swō | Cree Swō | Swā | Naskapi Swā | Cree Swā | - | |||
| S with ring diacritics | - | ᓮ | ᢾ | ᢿ | - | ||||||
| - | Sāi | Soy | Say | - | |||||||
| Naskapi compound letters | ᔌ | ᔍ | ᔏ | ᔎ | ᔊ | ||||||
| Spwa | Stwa | Scwa | Skwa | Skw | |||||||
Odia Sa


Sa (ସ) is a consonant of the Odia abugida. It ultimately arose from the Brahmi letter ![]() , via the Siddhaṃ letter
, via the Siddhaṃ letter ![]() Sa. Like in other Indic scripts, Odia consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Sa. Like in other Indic scripts, Odia consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
| Sa | Sā | Si | Sī | Su | Sū | Sr̥ | Sr̥̄ | Sl̥ | Sl̥̄ | Se | Sai | So | Sau | S |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ସ | ସା | ସି | ସୀ | ସୁ | ସୂ | ସୃ | ସୄ | ସୢ | ସୣ | ସେ | ସୈ | ସୋ | ସୌ | ସ୍ |
Conjuncts of ସ
As is common in Indic scripts, Odia joins letters together to form conjunct consonant clusters. The most common conjunct formation is achieved by using a small subjoined form of trailing consonants. Most consonants' subjoined forms are identical to the full form, just reduced in size, although a few drop the curved headline or have a subjoined form not directly related to the full form of the consonant. The second type of conjunct formation is through pure ligatures, where the constituent consonants are written together in a single graphic form. This ligature may be recognizable as being a combination of two characters or it can have a conjunct ligature unrelated to its constituent characters.
- ତ୍ (t) + ସ (sa) gives the ligature tsa:

Kaithi Sa


Sa (𑂮) is a consonant of the Kaithi abugida. It ultimately arose from the Brahmi letter ![]() , via the Siddhaṃ letter
, via the Siddhaṃ letter ![]() Sa. Like in other Indic scripts, Kaithi consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Sa. Like in other Indic scripts, Kaithi consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
| Sa | Sā | Si | Sī | Su | Sū | Se | Sai | So | Sau | S |
|---|---|---|---|---|---|---|---|---|---|---|
| 𑂮 | 𑂮𑂰 | 𑂮𑂱 | 𑂮𑂲 | 𑂮𑂳 | 𑂮𑂴 | 𑂮𑂵 | 𑂮𑂶 | 𑂮𑂷 | 𑂮𑂸 | 𑂮𑂹 |
Conjuncts of 𑂮
As is common in Indic scripts, Kaithi joins letters together to form conjunct consonant clusters. The most common conjunct formation is achieved by using a half form of preceding consonants, although several consonants use an explicit virama. Most half forms are derived from the full form by removing the vertical stem. As is common in most Indic scripts, conjucts of ra are indicated with a repha or rakar mark attached to the rest of the consonant cluster. In addition, there are a few vertical conjuncts that can be found in Kaithi writing, but true ligatures are not used in the modern Kaithi script.
- 𑂮୍ (s) + 𑂩 (ra) gives the ligature sra:

- 𑂩୍ (r) + 𑂮 (sa) gives the ligature rsa:

Comparison of Sa
The various Indic scripts are generally related to each other through adaptation and borrowing, and as such the glyphs for cognate letters, including Sa, are related as well.
| Comparison of Sa in different scripts |
|---|
|
Notes
|
Character encodings of Sa
Most Indic scripts are encoded in the Unicode Standard, and as such the letter Sa in those scripts can be represented in plain text with unique codepoint. Sa from several modern-use scripts can also be found in legacy encodings, such as ISCII.
| Preview | ஸ | స | ସ | ಸ | സ | સ | ਸ | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | DEVANAGARI LETTER SA | BENGALI LETTER SA | TAMIL LETTER SA | TELUGU LETTER SA | ORIYA LETTER SA | KANNADA LETTER SA | MALAYALAM LETTER SA | GUJARATI LETTER SA | GURMUKHI LETTER SA | |||||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 2360 | U+0938 | 2488 | U+09B8 | 3000 | U+0BB8 | 3128 | U+0C38 | 2872 | U+0B38 | 3256 | U+0CB8 | 3384 | U+0D38 | 2744 | U+0AB8 | 2616 | U+0A38 |
| UTF-8 | 224 164 184 | E0 A4 B8 | 224 166 184 | E0 A6 B8 | 224 174 184 | E0 AE B8 | 224 176 184 | E0 B0 B8 | 224 172 184 | E0 AC B8 | 224 178 184 | E0 B2 B8 | 224 180 184 | E0 B4 B8 | 224 170 184 | E0 AA B8 | 224 168 184 | E0 A8 B8 |
| Numeric character reference | स | स | স | স | ஸ | ஸ | స | స | ସ | ସ | ಸ | ಸ | സ | സ | સ | સ | ਸ | ਸ |
| ISCII | 215 | D7 | 215 | D7 | 215 | D7 | 215 | D7 | 215 | D7 | 215 | D7 | 215 | D7 | 215 | D7 | 215 | D7 |
| Preview | Ashoka Kushana Gupta | 𐨯 | 𑌸 | |||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | BRAHMI LETTER SA | KHAROSHTHI LETTER SA | SIDDHAM LETTER SA | GRANTHA LETTER SA | ||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 69682 | U+11032 | 68143 | U+10A2F | 71085 | U+115AD | 70456 | U+11338 |
| UTF-8 | 240 145 128 178 | F0 91 80 B2 | 240 144 168 175 | F0 90 A8 AF | 240 145 150 173 | F0 91 96 AD | 240 145 140 184 | F0 91 8C B8 |
| UTF-16 | 55300 56370 | D804 DC32 | 55298 56879 | D802 DE2F | 55301 56749 | D805 DDAD | 55300 57144 | D804 DF38 |
| Numeric character reference | 𑀲 | 𑀲 | 𐨯 | 𐨯 | 𑖭 | 𑖭 | 𑌸 | 𑌸 |
| Preview | ྶ | ꡛ | 𑨰 | 𑐳 | 𑰭 | 𑆱 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | TIBETAN LETTER SA | TIBETAN SUBJOINED LETTER SA | PHAGS-PA LETTER SA | ZANABAZAR SQUARE LETTER SA | NEWA LETTER SA | BHAIKSUKI LETTER SA | SHARADA LETTER SA | |||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 3942 | U+0F66 | 4022 | U+0FB6 | 43099 | U+A85B | 72240 | U+11A30 | 70707 | U+11433 | 72749 | U+11C2D | 70065 | U+111B1 |
| UTF-8 | 224 189 166 | E0 BD A6 | 224 190 182 | E0 BE B6 | 234 161 155 | EA A1 9B | 240 145 168 176 | F0 91 A8 B0 | 240 145 144 179 | F0 91 90 B3 | 240 145 176 173 | F0 91 B0 AD | 240 145 134 177 | F0 91 86 B1 |
| UTF-16 | 3942 | 0F66 | 4022 | 0FB6 | 43099 | A85B | 55302 56880 | D806 DE30 | 55301 56371 | D805 DC33 | 55303 56365 | D807 DC2D | 55300 56753 | D804 DDB1 |
| Numeric character reference | ས | ས | ྶ | ྶ | ꡛ | ꡛ | 𑨰 | 𑨰 | 𑐳 | 𑐳 | 𑰭 | 𑰭 | 𑆱 | 𑆱 |
| Preview | သ | ဿ | ᩈ | ᩞ | ᩔ | ᦉ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | MYANMAR LETTER SA | MYANMAR LETTER GREAT SA | TAI THAM LETTER HIGH SA | TAI THAM CONSONANT SIGN SA | TAI THAM LETTER GREAT SA | NEW TAI LUE LETTER HIGH SA | ||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 4126 | U+101E | 4159 | U+103F | 6728 | U+1A48 | 6750 | U+1A5E | 6740 | U+1A54 | 6537 | U+1989 |
| UTF-8 | 225 128 158 | E1 80 9E | 225 128 191 | E1 80 BF | 225 169 136 | E1 A9 88 | 225 169 158 | E1 A9 9E | 225 169 148 | E1 A9 94 | 225 166 137 | E1 A6 89 |
| Numeric character reference | သ | သ | ဿ | ဿ | ᩈ | ᩈ | ᩞ | ᩞ | ᩔ | ᩔ | ᦉ | ᦉ |
| Preview | ស | ສ | ส | ꪎ | ꪏ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | KHMER LETTER SA | LAO LETTER SO SUNG | THAI CHARACTER SO SUA | TAI VIET LETTER LOW SO | TAI VIET LETTER HIGH SO | |||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 6047 | U+179F | 3754 | U+0EAA | 3626 | U+0E2A | 43662 | U+AA8E | 43663 | U+AA8F |
| UTF-8 | 225 158 159 | E1 9E 9F | 224 186 170 | E0 BA AA | 224 184 170 | E0 B8 AA | 234 170 142 | EA AA 8E | 234 170 143 | EA AA 8F |
| Numeric character reference | ស | ស | ສ | ສ | ส | ส | ꪎ | ꪎ | ꪏ | ꪏ |
| Preview | ස | ꤎ | 𑄥 | ᥔ | 𑜏 | 𑤬 | ꢱ | ꨧ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | SINHALA LETTER DANTAJA SAYANNA | KAYAH LI LETTER SA | CHAKMA LETTER SAA | TAI LE LETTER SA | AHOM LETTER SA | DIVES AKURU LETTER SA | SAURASHTRA LETTER SA | CHAM LETTER SA | ||||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 3523 | U+0DC3 | 43278 | U+A90E | 69925 | U+11125 | 6484 | U+1954 | 71439 | U+1170F | 71980 | U+1192C | 43185 | U+A8B1 | 43559 | U+AA27 |
| UTF-8 | 224 183 131 | E0 B7 83 | 234 164 142 | EA A4 8E | 240 145 132 165 | F0 91 84 A5 | 225 165 148 | E1 A5 94 | 240 145 156 143 | F0 91 9C 8F | 240 145 164 172 | F0 91 A4 AC | 234 162 177 | EA A2 B1 | 234 168 167 | EA A8 A7 |
| UTF-16 | 3523 | 0DC3 | 43278 | A90E | 55300 56613 | D804 DD25 | 6484 | 1954 | 55301 57103 | D805 DF0F | 55302 56620 | D806 DD2C | 43185 | A8B1 | 43559 | AA27 |
| Numeric character reference | ස | ස | ꤎ | ꤎ | 𑄥 | 𑄥 | ᥔ | ᥔ | 𑜏 | 𑜏 | 𑤬 | 𑤬 | ꢱ | ꢱ | ꨧ | ꨧ |
| Preview | 𑘭 | 𑧍 | 𑪁 | ꠡ | 𑶉 | 𑂮 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | MODI LETTER SA | NANDINAGARI LETTER SA | SOYOMBO LETTER SA | SYLOTI NAGRI LETTER SO | GUNJALA GONDI LETTER SA | KAITHI LETTER SA | ||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 71213 | U+1162D | 72141 | U+119CD | 72321 | U+11A81 | 43041 | U+A821 | 73097 | U+11D89 | 69806 | U+110AE |
| UTF-8 | 240 145 152 173 | F0 91 98 AD | 240 145 167 141 | F0 91 A7 8D | 240 145 170 129 | F0 91 AA 81 | 234 160 161 | EA A0 A1 | 240 145 182 137 | F0 91 B6 89 | 240 145 130 174 | F0 91 82 AE |
| UTF-16 | 55301 56877 | D805 DE2D | 55302 56781 | D806 DDCD | 55302 56961 | D806 DE81 | 43041 | A821 | 55303 56713 | D807 DD89 | 55300 56494 | D804 DCAE |
| Numeric character reference | 𑘭 | 𑘭 | 𑧍 | 𑧍 | 𑪁 | 𑪁 | ꠡ | ꠡ | 𑶉 | 𑶉 | 𑂮 | 𑂮 |
| Preview | 𑒮 | ᰠ | ᤛ | ꯁ | 𑲍 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | TIRHUTA LETTER SA | LEPCHA LETTER SA | LIMBU LETTER SA | MEETEI MAYEK LETTER SAM | MARCHEN LETTER SA | |||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 70830 | U+114AE | 7200 | U+1C20 | 6427 | U+191B | 43969 | U+ABC1 | 72845 | U+11C8D |
| UTF-8 | 240 145 146 174 | F0 91 92 AE | 225 176 160 | E1 B0 A0 | 225 164 155 | E1 A4 9B | 234 175 129 | EA AF 81 | 240 145 178 141 | F0 91 B2 8D |
| UTF-16 | 55301 56494 | D805 DCAE | 7200 | 1C20 | 6427 | 191B | 43969 | ABC1 | 55303 56461 | D807 DC8D |
| Numeric character reference | 𑒮 | 𑒮 | ᰠ | ᰠ | ᤛ | ᤛ | ꯁ | ꯁ | 𑲍 | 𑲍 |
| Preview | 𑚨 | 𑠩 | 𑈩 | 𑋝 | 𑅰 | 𑊥 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | TAKRI LETTER SA | DOGRA LETTER SA | KHOJKI LETTER SA | KHUDAWADI LETTER SA | MAHAJANI LETTER SA | MULTANI LETTER SA | ||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 71336 | U+116A8 | 71721 | U+11829 | 70185 | U+11229 | 70365 | U+112DD | 70000 | U+11170 | 70309 | U+112A5 |
| UTF-8 | 240 145 154 168 | F0 91 9A A8 | 240 145 160 169 | F0 91 A0 A9 | 240 145 136 169 | F0 91 88 A9 | 240 145 139 157 | F0 91 8B 9D | 240 145 133 176 | F0 91 85 B0 | 240 145 138 165 | F0 91 8A A5 |
| UTF-16 | 55301 57000 | D805 DEA8 | 55302 56361 | D806 DC29 | 55300 56873 | D804 DE29 | 55300 57053 | D804 DEDD | 55300 56688 | D804 DD70 | 55300 56997 | D804 DEA5 |
| Numeric character reference | 𑚨 | 𑚨 | 𑠩 | 𑠩 | 𑈩 | 𑈩 | 𑋝 | 𑋝 | 𑅰 | 𑅰 | 𑊥 | 𑊥 |
| Preview | ᬲ | ᯘ | ᨔ | ꦱ | 𑻰 | ꤼ | ᮞ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | BALINESE LETTER SA | BATAK LETTER SA | BUGINESE LETTER SA | JAVANESE LETTER SA | MAKASAR LETTER SA | REJANG LETTER SA | SUNDANESE LETTER SA | |||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 6962 | U+1B32 | 7128 | U+1BD8 | 6676 | U+1A14 | 43441 | U+A9B1 | 73456 | U+11EF0 | 43324 | U+A93C | 7070 | U+1B9E |
| UTF-8 | 225 172 178 | E1 AC B2 | 225 175 152 | E1 AF 98 | 225 168 148 | E1 A8 94 | 234 166 177 | EA A6 B1 | 240 145 187 176 | F0 91 BB B0 | 234 164 188 | EA A4 BC | 225 174 158 | E1 AE 9E |
| UTF-16 | 6962 | 1B32 | 7128 | 1BD8 | 6676 | 1A14 | 43441 | A9B1 | 55303 57072 | D807 DEF0 | 43324 | A93C | 7070 | 1B9E |
| Numeric character reference | ᬲ | ᬲ | ᯘ | ᯘ | ᨔ | ᨔ | ꦱ | ꦱ | 𑻰 | 𑻰 | ꤼ | ꤼ | ᮞ | ᮞ |
| Preview | ᜐ | ᝰ | ᝐ | ᜰ | 𑴫 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | TAGALOG LETTER SA | TAGBANWA LETTER SA | BUHID LETTER SA | HANUNOO LETTER SA | MASARAM GONDI LETTER SA | |||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 5904 | U+1710 | 6000 | U+1770 | 5968 | U+1750 | 5936 | U+1730 | 73003 | U+11D2B |
| UTF-8 | 225 156 144 | E1 9C 90 | 225 157 176 | E1 9D B0 | 225 157 144 | E1 9D 90 | 225 156 176 | E1 9C B0 | 240 145 180 171 | F0 91 B4 AB |
| UTF-16 | 5904 | 1710 | 6000 | 1770 | 5968 | 1750 | 5936 | 1730 | 55303 56619 | D807 DD2B |
| Numeric character reference | ᜐ | ᜐ | ᝰ | ᝰ | ᝐ | ᝐ | ᜰ | ᜰ | 𑴫 | 𑴫 |
| Preview | ᓭ | ᓯ | ᓱ | ᓴ | ᔅ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | CANADIAN SYLLABICS SE | CANADIAN SYLLABICS SI | CANADIAN SYLLABICS SO | CANADIAN SYLLABICS SA | CANADIAN SYLLABICS S | |||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 5357 | U+14ED | 5359 | U+14EF | 5361 | U+14F1 | 5364 | U+14F4 | 5381 | U+1505 |
| UTF-8 | 225 147 173 | E1 93 AD | 225 147 175 | E1 93 AF | 225 147 177 | E1 93 B1 | 225 147 180 | E1 93 B4 | 225 148 133 | E1 94 85 |
| Numeric character reference | ᓭ | ᓭ | ᓯ | ᓯ | ᓱ | ᓱ | ᓴ | ᓴ | ᔅ | ᔅ |
- The full range of SE Canadian syllabic characters can be found at the codepoint ranges 14ED-1505, 1507, 1509-150F, 18BE-18BF, 18DA.
References
- ↑ Ifrah, Georges (2000). The Universal History of Numbers. From Prehistory to the Invention of the Computer. New York: John Wiley & Sons. pp. 447–450. ISBN 0-471-39340-1.
- 1 2 Bühler, Georg (1898). "On the Origin of the Indian Brahmi Alphabet". archive.org. Karl J. Trübner. Retrieved 10 June 2020.
- ↑ Evolutionary chart, Journal of the Asiatic Society of Bengal Vol 7, 1838
- ↑ Pall, Peeter. "Microsoft Word - kblhi2" (PDF). Eesti Keele Instituudi kohanimeandmed. Eesti Keele Instituudi kohanimeandmed. Retrieved 19 June 2020.
- ↑ "The Bengali Alphabet" (PDF). Archived from the original (PDF) on 2013-09-28.
- ↑ Andrew Dalby (2004:139) Dictionary of Languages
- ↑ Some General Aspects of the Syllabics Orthography, Chris Harvey 2003